Contenido
Pandas¶
¿A que nos sirve?¶
Con Pandas podemos manejar nuestros datos, modificandolos, transformandolos y analizandolos.
En particular podemos:
limpiar los datos presentes en un DataFrame
Visualizar los datos con la ayuda de Matplotlib
Almacenar los datos trasformados en otro archivo CSV
Panda está construido con base en Numpy y normalmente su output preferido es Scipy o Scikit-learn.
Antes que todo tendremos que importar los paquetes:
import pandas as pd
import numpy as np
Merge and append¶
Una de las cosas que utilizaremos más cuando harémos data cleaning es juntar data frame así de poder obtener una base más funcional. Para hacer esto tenemos diferentes funciones con Python.
Antes de ver los Join analizaremos como podemos concatenar data frames:
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
df2 = pd.DataFrame(
{
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
},
)
df3 = pd.DataFrame(
{
"A": ["A8", "A9", "A10", "A11"],
"B": ["B8", "B9", "B10", "B11"],
"C": ["C8", "C9", "C10", "C11"],
"D": ["D8", "D9", "D10", "D11"],
},
index=[8, 9, 10, 11],
)
frames = [df1, df2, df3]
result = pd.concat(frames)
result
| A | B | C | D | |
|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | D2 |
| 3 | A3 | B3 | C3 | D3 |
| 0 | A4 | B4 | C4 | D4 |
| 1 | A5 | B5 | C5 | D5 |
| 2 | A6 | B6 | C6 | D6 |
| 3 | A7 | B7 | C7 | D7 |
| 8 | A8 | B8 | C8 | D8 |
| 9 | A9 | B9 | C9 | D9 |
| 10 | A10 | B10 | C10 | D10 |
| 11 | A11 | B11 | C11 | D11 |
Nuestra función tiene las siguientes propriedades:
pd.concat( objs, axis=0, join=»outer», ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True, )
result = pd.concat(frames, keys=["x", "y", "z"])
result
| A | B | C | D | ||
|---|---|---|---|---|---|
| x | 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 | |
| 2 | A2 | B2 | C2 | D2 | |
| 3 | A3 | B3 | C3 | D3 | |
| y | 0 | A4 | B4 | C4 | D4 |
| 1 | A5 | B5 | C5 | D5 | |
| 2 | A6 | B6 | C6 | D6 | |
| 3 | A7 | B7 | C7 | D7 | |
| z | 8 | A8 | B8 | C8 | D8 |
| 9 | A9 | B9 | C9 | D9 | |
| 10 | A10 | B10 | C10 | D10 | |
| 11 | A11 | B11 | C11 | D11 |
Tendremos por lo tanto un objecto con un idnice jerarquizado:
result.loc["y"]
| A | B | C | D | |
|---|---|---|---|---|
| 0 | A4 | B4 | C4 | D4 |
| 1 | A5 | B5 | C5 | D5 |
| 2 | A6 | B6 | C6 | D6 |
| 3 | A7 | B7 | C7 | D7 |
Podemos tambien definir el eje de donde queremos hacer el appen y decidir si queremos la union (join=outer) o la interseccion (join=inner):
df4 = pd.DataFrame(
{
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
},
index=[2, 3, 6, 7],
)
result = pd.concat([df1, df4], axis=1)
result
| A | B | C | D | B | D | F | |
|---|---|---|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 | NaN | NaN | NaN |
| 1 | A1 | B1 | C1 | D1 | NaN | NaN | NaN |
| 2 | A2 | B2 | C2 | D2 | B2 | D2 | F2 |
| 3 | A3 | B3 | C3 | D3 | B3 | D3 | F3 |
| 6 | NaN | NaN | NaN | NaN | B6 | D6 | F6 |
| 7 | NaN | NaN | NaN | NaN | B7 | D7 | F7 |
result = pd.concat([df1, df4], axis=1, join="inner")
result
| A | B | C | D | B | D | F | |
|---|---|---|---|---|---|---|---|
| 2 | A2 | B2 | C2 | D2 | B2 | D2 | F2 |
| 3 | A3 | B3 | C3 | D3 | B3 | D3 | F3 |
Para concatenar podemos utilizar tambien el append, de hecho era una función antes del concat y funciona solo pr el eje 0, nuestros renglones:
result = df1.append(df2)
result
| A | B | C | D | |
|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | D2 |
| 3 | A3 | B3 | C3 | D3 |
| 0 | A4 | B4 | C4 | D4 |
| 1 | A5 | B5 | C5 | D5 |
| 2 | A6 | B6 | C6 | D6 |
| 3 | A7 | B7 | C7 | D7 |
¿Qué pasa si hacemos un append de los siguientes dataframes?
df1
| A | B | C | D | |
|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | D2 |
| 3 | A3 | B3 | C3 | D3 |
df4
| B | D | F | |
|---|---|---|---|
| 2 | B2 | D2 | F2 |
| 3 | B3 | D3 | F3 |
| 6 | B6 | D6 | F6 |
| 7 | B7 | D7 | F7 |
result = df1.append(df4, sort=False)
result
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 | NaN |
| 1 | A1 | B1 | C1 | D1 | NaN |
| 2 | A2 | B2 | C2 | D2 | NaN |
| 3 | A3 | B3 | C3 | D3 | NaN |
| 2 | NaN | B2 | NaN | D2 | F2 |
| 3 | NaN | B3 | NaN | D3 | F3 |
| 6 | NaN | B6 | NaN | D6 | F6 |
| 7 | NaN | B7 | NaN | D7 | F7 |
Podemos hacer append de multiples dataframe a la vez:
result = df1.append([df2, df3])
result
| A | B | C | D | |
|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | D2 |
| 3 | A3 | B3 | C3 | D3 |
| 0 | A4 | B4 | C4 | D4 |
| 1 | A5 | B5 | C5 | D5 |
| 2 | A6 | B6 | C6 | D6 |
| 3 | A7 | B7 | C7 | D7 |
| 8 | A8 | B8 | C8 | D8 |
| 9 | A9 | B9 | C9 | D9 |
| 10 | A10 | B10 | C10 | D10 |
| 11 | A11 | B11 | C11 | D11 |
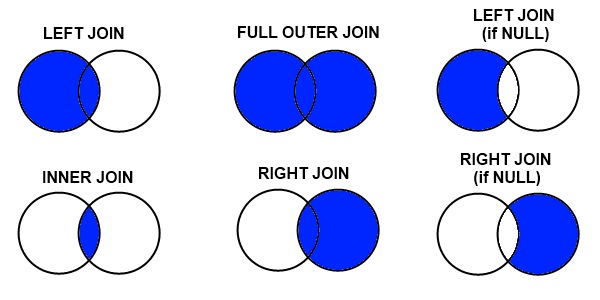
Merge¶
Pandas nos permite de juntar dataframe de manera computacionalmente eficaz con una sintaxis similar a la de SQL. Resulta mucho más eficaz que otros lenguajes como R. Tenemos una unica función atraves de la cual, especificando los distintos argumentos, podemos obtener los diferentes join:
pd.merge( left, right, how=»inner», on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=(«_x», «_y»), copy=True, indicator=False, validate=None, )
Uno de los conceptos principales es el tipo de relación que tenemos entre las llaves de los distintos data frames:
1:1: juntamos los dos data frames por medio de una llave que debe ser unica
m:1: la llave unica es presente solo en el segundo data frame, en el primero puede ser repetida
m:m: el join viene efectuado sobre columna, si la llave que nos sirve para juntar los data frames es repetida obtendremos un producto cartesiano de los dos data frames
left = pd.DataFrame(
{
"key": ["K0", "K1", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
right = pd.DataFrame(
{
"key": ["K0", "K1", "K2", "K3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
left
| key | A | B | |
|---|---|---|---|
| 0 | K0 | A0 | B0 |
| 1 | K1 | A1 | B1 |
| 2 | K2 | A2 | B2 |
| 3 | K3 | A3 | B3 |
right
| key | C | D | |
|---|---|---|---|
| 0 | K0 | C0 | D0 |
| 1 | K1 | C1 | D1 |
| 2 | K2 | C2 | D2 |
| 3 | K3 | C3 | D3 |
result = pd.merge(left, right, on="key")
result
| key | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | A1 | B1 | C1 | D1 |
| 2 | K2 | A2 | B2 | C2 | D2 |
| 3 | K3 | A3 | B3 | C3 | D3 |
Podemos tener llaves multiples:
left = pd.DataFrame(
{
"key1": ["K0", "K0", "K1", "K2"],
"key2": ["K0", "K1", "K0", "K1"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
right = pd.DataFrame(
{
"key1": ["K0", "K1", "K1", "K2"],
"key2": ["K0", "K0", "K0", "K0"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
left
| key1 | key2 | A | B | |
|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 |
| 1 | K0 | K1 | A1 | B1 |
| 2 | K1 | K0 | A2 | B2 |
| 3 | K2 | K1 | A3 | B3 |
right
| key1 | key2 | C | D | |
|---|---|---|---|---|
| 0 | K0 | K0 | C0 | D0 |
| 1 | K1 | K0 | C1 | D1 |
| 2 | K1 | K0 | C2 | D2 |
| 3 | K2 | K0 | C3 | D3 |
result = pd.merge(left, right, )on=["key1", "key2"]
result
File "<ipython-input-20-f84d9bef89ee>", line 1
result = pd.merge(left, right, )on=["key1", "key2"]
^
SyntaxError: invalid syntax
Tipos Join¶
En el argumento how podemos especificar que tipo de join queremos efectuar:
left: left outer join, utilizamos las llaves del df de la izquierda
right: right outer join, utilizamos las llaves del df de la derecha
outer:utilizamos la union de las llaves de ambos df
inner: utilizamos la intersección entre las dos llaves
result = pd.merge(left, right, how="left", on=["key1", "key2"])
result
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K0 | K1 | A1 | B1 | NaN | NaN |
| 2 | K1 | K0 | A2 | B2 | C1 | D1 |
| 3 | K1 | K0 | A2 | B2 | C2 | D2 |
| 4 | K2 | K1 | A3 | B3 | NaN | NaN |
result = pd.merge(left, right, how="right", on=["key1", "key2"])
result
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | K0 | A2 | B2 | C1 | D1 |
| 2 | K1 | K0 | A2 | B2 | C2 | D2 |
| 3 | K2 | K0 | NaN | NaN | C3 | D3 |
result = pd.merge(left, right, how="outer", on=["key1", "key2"])
result
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K0 | K1 | A1 | B1 | NaN | NaN |
| 2 | K1 | K0 | A2 | B2 | C1 | D1 |
| 3 | K1 | K0 | A2 | B2 | C2 | D2 |
| 4 | K2 | K1 | A3 | B3 | NaN | NaN |
| 5 | K2 | K0 | NaN | NaN | C3 | D3 |
result = pd.merge(left, right, how="inner", on=["key1", "key2"])
result
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | K0 | A2 | B2 | C1 | D1 |
| 2 | K1 | K0 | A2 | B2 | C2 | D2 |
Tenemos que estar cuidados cuando tenemos indices multiples
SQL¶
¿Qué es SQL?¶
SQL son las siglas de Structured Query Language
SQL permite acceder y manipular bases de datos
SQL se convirtió en un estándar del American National Standards Institute (ANSI) en 1986, y de la International Organization for Standardization (ISO) en 1987.
A pesar de ser estándar hay diferentes «mutaciones» de SQL
¿Qué podemos hacer con SQL?¶
ejecutar consultas en una base de datos
recuperar datos de una base de datos
insertar registros en una base de datos
actualizar registros en una base de datos
eliminar registros de una base de datos
crear nuevas bases de datos
crear nuevas tablas en una base de datos
crear procedimientos almacenados en una base de datos
crear vistas en una base de datos
establecer permisos en tablas, procedimientos y vistas
RDBMS¶
RDBMS son las siglas de Relational Database Management System.
RDBMS es la base de SQL y de todos los sistemas de bases de datos modernos como MS SQL Server, IBM DB2, Oracle, MySQL y Microsoft Access.
Los datos en RDBMS se almacenan en objetos llamados tablas. Una tabla es una colección de entradas de datos relacionados y consta de columnas y filas.
Cada tabla se divide en entidades más pequeñas llamadas campos. Los campos de la tabla Clientes constan de CustomerID, CustomerName, ContactName, Address, City, PostalCode y Country. Un campo es una columna de una tabla diseñada para mantener información específica sobre cada registro de la tabla.
Un registro, también llamado fila, es cada entrada individual que existe en una tabla. Un registro es una entidad horizontal en una tabla.
Una columna es una entidad vertical en una tabla que contiene toda la información asociada con un campo específico en una tabla.
Tablas¶
Una base de datos suele contener una o más tablas. Cada tabla se identifica con un nombre (por ejemplo, «Clientes» u «Pedidos»). Las tablas contienen registros (filas) con datos.

Tenemos 5 records y 7 campos.
SQL Statements¶
Los statements son la sintaxis através de las cuales pedimos informaciones o modificaciones a la base de datos.
** A diferencia que en Python los statements no son case sensitive **
SELECT * FROM Customers;
SELECT: extrae datos de una base de datosUPDATE: actualiza los datos en una base de datosDELETE: elimina datos de una base de datosINSERT INTO: inserta nuevos datos en una base de datosCREATE DATABASE: crea una nueva base de datosALTER DATABASE: modifica una base de datosCREATE TABLE: crea una nueva tablaALTER TABLE: modifica una tablaDROP TABLE:elimina una tablaCREATE INDEX: crea un índice (clave de búsqueda)DROP INDEX: elimina un índice
La instrucción SELECT se utiliza para seleccionar datos de una base de datos.
Los datos devueltos se almacenan en una tabla de resultados, denominada conjunto result set.
SELECT column1, column2, ...
FROM table_name;
SELECT * FROM table_name;
Si queremos seleccionar solo valores distintos utilizaremos el siguiente comando:
SELECT DISTINCT column1, column2, ...
FROM table_name;
Si queremos saber cuantos valores distintos tenemos para cada campo usaremos:
SELECT COUNT(DISTINCT Country) FROM Customers;
Cuando queremos especificar alguna condición parrticular utilizaremos el where:
SELECT column1, column2, ...
FROM table_name
WHERE condition;
SELECT * FROM Customers
WHERE Country='Mexico';
Si queremos poner una condición numerica:
SELECT * FROM Customers
WHERE CustomerID=1;
Las condiciones que podemos utilizar son ligeramente diferente con respecto a python:

La condición de where podemos combinarla con los operadores AND,OR,NOT
SELECT column1, column2, ...
FROM table_name
WHERE condition1 AND condition2 OR condition3 ...;
SELECT column1, column2, ...
FROM table_name
WHERE NOT condition;
SELECT * FROM Customers
WHERE Country='Germany' AND (City='Berlin' OR City='München');
Para ordenar nuestra tabolas de resultados podemos utilizar el ORDER BY:
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;
Podemos utilizar más de un orden como vimos en Pandas:
SELECT * FROM Customers
ORDER BY Country, CustomerName;
para manejar los NULL, que son los equivalente de los NA de pandas, podemos utilziar las operadores IS NULL y IS NOT NULL
SELECT CustomerName, ContactName, Address
FROM Customers
WHERE Address IS NULL;
Con UPDATE podemos utiliactualziar los records:
UPDATE Customers
SET ContactName = 'Alfred Schmidt', City= 'Frankfurt'
WHERE CustomerID = 1;
SELECT COUNT(column_name)
FROM table_name
WHERE condition;
SELECT SUM(column_name)
FROM table_name
WHERE condition;
SELECT AVG(column_name)
FROM table_name
WHERE condition;
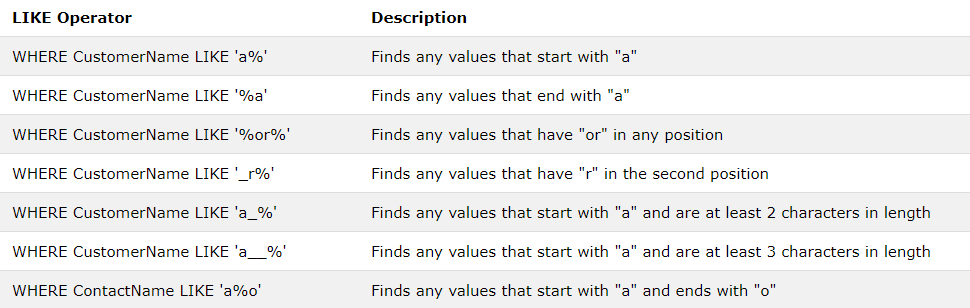
Otra función muy utili es el like: