
Contenido
EDA¶
¿Qué es?¶
La EDA (Exploratory Data Anlayisis) nos permite analizar los datos que tenemos en un database de manera intuitiva y grafíca asi de poder mejor comprender sus peculiaridades y llegar a una mejor comprensión así de facilitar las fases sucesivas.
La definición formal es:
En estadística, el análisis exploratorio de datos es un enfoque para analizar conjuntos de datos para resumir sus principales características, a menudo con métodos visuales. Se puede usar o no un modelo estadístico, pero principalmente EDA es para ver qué nos pueden decir los datos más allá del modelado formal o la tarea de prueba de hipótesis.
Podemos por lo tanto tener unos insight que nos serán utilzes luego tanto para preparar los datos para las faces sucesivas (removiendo las irregularidades) y tener una visión aproximativa de los mismos.
Basandonos en este anlísis podemos empezar a toamr algunas decisiones en la estructuración de los datos y en la definición de los modelos a utilizar:
si la hacemos bien podemos ahorrarnos mucho trabajo
si la hacemos mal arriesgamos a perder información valiosa
Temos 5 fases principales en el EDA:
Recompilación y carga de datos
Limpieza datos
Analísis univariada
Analísis bivariada
Analísis multivariada
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
Recompilación y carga de datos¶
Ya vimos en varios laboratorios como podemos cargar los datos de diferentes archivos, con apis e introducirlos manualmente. Cuidados con las fuentes de los datos y como tenemos que citarlos y como lo podemos compartir.
Subimos por lo tantos los datos que pueden encontrar aquí para replicas.
db=pd.read_csv("Marketing_Analysis.csv",low_memory=False)
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-2-469d18f944a3> in <module>
----> 1 db=pd.read_csv("Marketing_Analysis.csv",low_memory=False)
~/opt/anaconda3/lib/python3.8/site-packages/pandas/io/parsers.py in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
684 )
685
--> 686 return _read(filepath_or_buffer, kwds)
687
688
~/opt/anaconda3/lib/python3.8/site-packages/pandas/io/parsers.py in _read(filepath_or_buffer, kwds)
450
451 # Create the parser.
--> 452 parser = TextFileReader(fp_or_buf, **kwds)
453
454 if chunksize or iterator:
~/opt/anaconda3/lib/python3.8/site-packages/pandas/io/parsers.py in __init__(self, f, engine, **kwds)
944 self.options["has_index_names"] = kwds["has_index_names"]
945
--> 946 self._make_engine(self.engine)
947
948 def close(self):
~/opt/anaconda3/lib/python3.8/site-packages/pandas/io/parsers.py in _make_engine(self, engine)
1176 def _make_engine(self, engine="c"):
1177 if engine == "c":
-> 1178 self._engine = CParserWrapper(self.f, **self.options)
1179 else:
1180 if engine == "python":
~/opt/anaconda3/lib/python3.8/site-packages/pandas/io/parsers.py in __init__(self, src, **kwds)
2006 kwds["usecols"] = self.usecols
2007
-> 2008 self._reader = parsers.TextReader(src, **kwds)
2009 self.unnamed_cols = self._reader.unnamed_cols
2010
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader.__cinit__()
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source()
FileNotFoundError: [Errno 2] No such file or directory: 'Marketing_Analysis.csv'
db.shape
(45211, 19)
db.head(5)
| customerid | age | salary | balance | marital | jobedu | targeted | default | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | response | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 58.0 | 100000 | 2143 | married | management,tertiary | yes | no | yes | no | unknown | 5 | may, 2017 | 261 sec | 1 | -1 | 0 | unknown | no |
| 1 | 2 | 44.0 | 60000 | 29 | single | technician,secondary | yes | no | yes | no | unknown | 5 | may, 2017 | 151 sec | 1 | -1 | 0 | unknown | no |
| 2 | 3 | 33.0 | 120000 | 2 | married | entrepreneur,secondary | yes | no | yes | yes | unknown | 5 | may, 2017 | 76 sec | 1 | -1 | 0 | unknown | no |
| 3 | 4 | 47.0 | 20000 | 1506 | married | blue-collar,unknown | no | no | yes | no | unknown | 5 | may, 2017 | 92 sec | 1 | -1 | 0 | unknown | no |
| 4 | 5 | 33.0 | 0 | 1 | single | unknown,unknown | no | no | no | no | unknown | 5 | may, 2017 | 198 sec | 1 | -1 | 0 | unknown | no |
db.set_index("customerid", inplace= True)
db.head(3)
| age | salary | balance | marital | jobedu | targeted | default | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | response | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| customerid | ||||||||||||||||||
| 1 | 58.0 | 100000 | 2143 | married | management,tertiary | yes | no | yes | no | unknown | 5 | may, 2017 | 261 sec | 1 | -1 | 0 | unknown | no |
| 2 | 44.0 | 60000 | 29 | single | technician,secondary | yes | no | yes | no | unknown | 5 | may, 2017 | 151 sec | 1 | -1 | 0 | unknown | no |
| 3 | 33.0 | 120000 | 2 | married | entrepreneur,secondary | yes | no | yes | yes | unknown | 5 | may, 2017 | 76 sec | 1 | -1 | 0 | unknown | no |
db.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 45211 entries, 1 to 45211
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 45191 non-null float64
1 salary 45211 non-null int64
2 balance 45211 non-null int64
3 marital 45211 non-null object
4 jobedu 45211 non-null object
5 targeted 45211 non-null object
6 default 45211 non-null object
7 housing 45211 non-null object
8 loan 45211 non-null object
9 contact 45211 non-null object
10 day 45211 non-null int64
11 month 45161 non-null object
12 duration 45211 non-null object
13 campaign 45211 non-null int64
14 pdays 45211 non-null int64
15 previous 45211 non-null int64
16 poutcome 45211 non-null object
17 response 45181 non-null object
dtypes: float64(1), int64(6), object(11)
memory usage: 6.6+ MB
db.columns
Index(['age', 'salary', 'balance', 'marital', 'jobedu', 'targeted', 'default',
'housing', 'loan', 'contact', 'day', 'month', 'duration', 'campaign',
'pdays', 'previous', 'poutcome', 'response'],
dtype='object')
Ahora si nada más checkamos valores null:
db.isnull().sum()
age 20
salary 0
balance 0
marital 0
jobedu 0
targeted 0
default 0
housing 0
loan 0
contact 0
day 0
month 50
duration 0
campaign 0
pdays 0
previous 0
poutcome 0
response 30
dtype: int64
2. Limpieza datos¶
Ahora procedemos a la limpieza del D:
Eliminamos eventuales columnas/renglones de resume
Unimos eventualmetne columna para entender mejor los datos
de igual forma dividir eventaules otras columnas
Averiguamos que todos las columnas tengan nombre y sobre todo el indice
En nuestro caso tenemos:
db.head(5)
| age | salary | balance | marital | jobedu | targeted | default | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | response | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| customerid | ||||||||||||||||||
| 1 | 58.0 | 100000 | 2143 | married | management,tertiary | yes | no | yes | no | unknown | 5 | may, 2017 | 261 sec | 1 | -1 | 0 | unknown | no |
| 2 | 44.0 | 60000 | 29 | single | technician,secondary | yes | no | yes | no | unknown | 5 | may, 2017 | 151 sec | 1 | -1 | 0 | unknown | no |
| 3 | 33.0 | 120000 | 2 | married | entrepreneur,secondary | yes | no | yes | yes | unknown | 5 | may, 2017 | 76 sec | 1 | -1 | 0 | unknown | no |
| 4 | 47.0 | 20000 | 1506 | married | blue-collar,unknown | no | no | yes | no | unknown | 5 | may, 2017 | 92 sec | 1 | -1 | 0 | unknown | no |
| 5 | 33.0 | 0 | 1 | single | unknown,unknown | no | no | no | no | unknown | 5 | may, 2017 | 198 sec | 1 | -1 | 0 | unknown | no |
¿Qué notamos?
db['job']= db["jobedu"].apply(lambda x: x.split(",")[0])
db['education']= db["jobedu"].apply(lambda x: x.split(",")[1])
db
| age | salary | balance | marital | jobedu | targeted | default | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | response | job | education | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| customerid | ||||||||||||||||||||
| 1 | 58.0 | 100000 | 2143 | married | management,tertiary | yes | no | yes | no | unknown | 5 | may, 2017 | 261 sec | 1 | -1 | 0 | unknown | no | management | tertiary |
| 2 | 44.0 | 60000 | 29 | single | technician,secondary | yes | no | yes | no | unknown | 5 | may, 2017 | 151 sec | 1 | -1 | 0 | unknown | no | technician | secondary |
| 3 | 33.0 | 120000 | 2 | married | entrepreneur,secondary | yes | no | yes | yes | unknown | 5 | may, 2017 | 76 sec | 1 | -1 | 0 | unknown | no | entrepreneur | secondary |
| 4 | 47.0 | 20000 | 1506 | married | blue-collar,unknown | no | no | yes | no | unknown | 5 | may, 2017 | 92 sec | 1 | -1 | 0 | unknown | no | blue-collar | unknown |
| 5 | 33.0 | 0 | 1 | single | unknown,unknown | no | no | no | no | unknown | 5 | may, 2017 | 198 sec | 1 | -1 | 0 | unknown | no | unknown | unknown |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 45207 | 51.0 | 60000 | 825 | married | technician,tertiary | yes | no | no | no | cellular | 17 | nov, 2017 | 16.2833333333333 min | 3 | -1 | 0 | unknown | yes | technician | tertiary |
| 45208 | 71.0 | 55000 | 1729 | divorced | retired,primary | yes | no | no | no | cellular | 17 | nov, 2017 | 7.6 min | 2 | -1 | 0 | unknown | yes | retired | primary |
| 45209 | 72.0 | 55000 | 5715 | married | retired,secondary | yes | no | no | no | cellular | 17 | nov, 2017 | 18.7833333333333 min | 5 | 184 | 3 | success | yes | retired | secondary |
| 45210 | 57.0 | 20000 | 668 | married | blue-collar,secondary | yes | no | no | no | telephone | 17 | nov, 2017 | 8.46666666666667 min | 4 | -1 | 0 | unknown | no | blue-collar | secondary |
| 45211 | 37.0 | 120000 | 2971 | married | entrepreneur,secondary | yes | no | no | no | cellular | 17 | nov, 2017 | 6.01666666666667 min | 2 | 188 | 11 | other | no | entrepreneur | secondary |
45211 rows × 20 columns
db.drop(labels='jobedu', axis = 1, inplace = True)
db
| age | salary | balance | marital | targeted | default | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | response | job | education | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| customerid | |||||||||||||||||||
| 1 | 58.0 | 100000 | 2143 | married | yes | no | yes | no | unknown | 5 | may, 2017 | 261 sec | 1 | -1 | 0 | unknown | no | management | tertiary |
| 2 | 44.0 | 60000 | 29 | single | yes | no | yes | no | unknown | 5 | may, 2017 | 151 sec | 1 | -1 | 0 | unknown | no | technician | secondary |
| 3 | 33.0 | 120000 | 2 | married | yes | no | yes | yes | unknown | 5 | may, 2017 | 76 sec | 1 | -1 | 0 | unknown | no | entrepreneur | secondary |
| 4 | 47.0 | 20000 | 1506 | married | no | no | yes | no | unknown | 5 | may, 2017 | 92 sec | 1 | -1 | 0 | unknown | no | blue-collar | unknown |
| 5 | 33.0 | 0 | 1 | single | no | no | no | no | unknown | 5 | may, 2017 | 198 sec | 1 | -1 | 0 | unknown | no | unknown | unknown |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 45207 | 51.0 | 60000 | 825 | married | yes | no | no | no | cellular | 17 | nov, 2017 | 16.2833333333333 min | 3 | -1 | 0 | unknown | yes | technician | tertiary |
| 45208 | 71.0 | 55000 | 1729 | divorced | yes | no | no | no | cellular | 17 | nov, 2017 | 7.6 min | 2 | -1 | 0 | unknown | yes | retired | primary |
| 45209 | 72.0 | 55000 | 5715 | married | yes | no | no | no | cellular | 17 | nov, 2017 | 18.7833333333333 min | 5 | 184 | 3 | success | yes | retired | secondary |
| 45210 | 57.0 | 20000 | 668 | married | yes | no | no | no | telephone | 17 | nov, 2017 | 8.46666666666667 min | 4 | -1 | 0 | unknown | no | blue-collar | secondary |
| 45211 | 37.0 | 120000 | 2971 | married | yes | no | no | no | cellular | 17 | nov, 2017 | 6.01666666666667 min | 2 | 188 | 11 | other | no | entrepreneur | secondary |
45211 rows × 19 columns
Ahora manejamos los valores faltantes, podemos tener de tres tipos:
MCAR(Missing completely at random): no dependen de alguna caracteristica en particular
MAR(Missing at random): pueden depender de alguna caracteristica
MNAR(Missing not at random): hay alguna razón para faltar
Droppamos todos lo que no tienen edad definida:
db = db[~db.age.isnull()].copy()
db.isnull().sum()
db.shape
(45161, 20)
Ahora imputamos los valores para los meses:
month_mode = db.month.mode()[0]
month_mode
'may, 2017'
Ahora procedemos a substituir este valor en nuestra columna con faltante:
db.month.fillna(month_mode, inplace = True)
db.month.isnull().sum()
0
Ahora manejamos los faltantes en nuestra variable dependiente (response):
db = db[~db.response.isnull()].copy()
db.isnull().sum()
age 0
salary 0
balance 0
marital 0
targeted 0
default 0
housing 0
loan 0
contact 0
day 0
month 0
duration 0
campaign 0
pdays 0
previous 0
poutcome 0
response 0
job 0
education 0
dtype: int64
Podriamos sobstituir nuestro valores faltantes con NaN para que no haya afectaciones cuando procedemos al analisís estadistico
Outliers¶
Son unos datos que se discostan remarcablemente del siguiente punto más cercano. Podemos tener:
Outlier univariado
Outlier multivariado/bivariado: cuando ploteamos una variable con otra el valor se discosta del valor esperado de manera anormal
Antes de proceder a eso tenemos que estandardizar los valores para que escalas diferentes no nos lleven a conclusiones equivocadas. Tenemos diferentes tipologias de datos que podemos encontrar
Analisis univariado de variable categorica no ordenada¶
no tienen peso o medida
no tienen orden
db.job.value_counts()
blue-collar 9722
management 9451
technician 7589
admin. 5165
services 4148
retired 2262
self-employed 1574
entrepreneur 1484
unemployed 1302
housemaid 1238
student 938
unknown 288
Name: job, dtype: int64
db.job.value_counts(normalize=True)
blue-collar 0.215274
management 0.209273
technician 0.168043
admin. 0.114369
services 0.091849
retired 0.050087
self-employed 0.034853
entrepreneur 0.032860
unemployed 0.028830
housemaid 0.027413
student 0.020770
unknown 0.006377
Name: job, dtype: float64
Podemo plotear nuestro analisis:
db.job.value_counts(normalize=True).plot.barh()
plt.show()
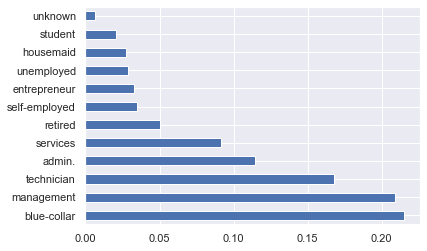
Analisis univariada Variable categorica ordenada¶
Estas variables tienen un orden natural, por ejemplo:
Meses
Educación
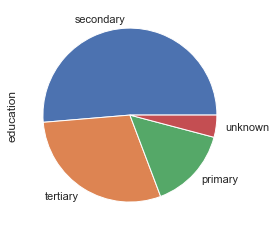
db.education.value_counts(normalize=True)
db.education.value_counts().plot.pie()
plt.show()
Si tenemos una variable con valores numericos podemos calcular
db.salary.describe()
count 45161.000000
mean 57004.849317
std 32087.698810
min 0.000000
25% 20000.000000
50% 60000.000000
75% 70000.000000
max 120000.000000
Name: salary, dtype: float64
Finalmente podemos plotear una densidad de la distribución de la varaible numerica:
sns.distplot(db['salary'])
C:\ProgramData\Anaconda3\lib\site-packages\seaborn\distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
<AxesSubplot:xlabel='salary', ylabel='Density'>
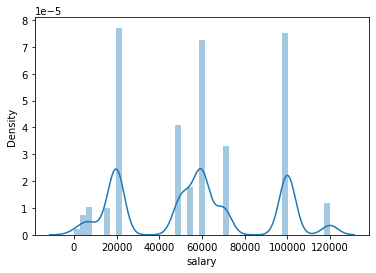
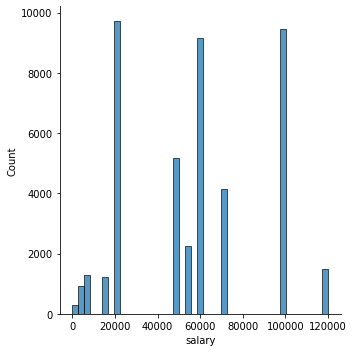
sns.displot(db['salary'])
<seaborn.axisgrid.FacetGrid at 0x15f1d76c348>
sns.histplot(db['balance'])
plt.xlim(-8019, 102127)
plt.ylim(0,3000)
(0.0, 3000.0)
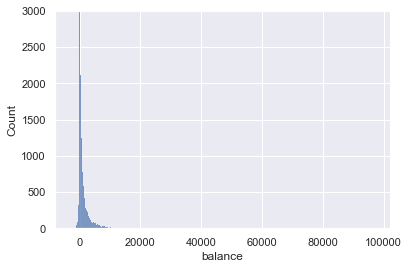
db.balance.describe()
count 45161.000000
mean 1362.850690
std 3045.939589
min -8019.000000
25% 72.000000
50% 448.000000
75% 1428.000000
max 102127.000000
Name: balance, dtype: float64
Analisis bivariada¶
Cuando hacemos un analisis bivariada el uso de graficas nos puede ser extremadamente utíl. En particular los más ocupados son:
scatter plot
pair plot
matriz de correlación
Scatter plot¶
plt.scatter(db.salary,db.balance)
plt.show()
db.plot.scatter(x="age",y="balance")
plt.show()
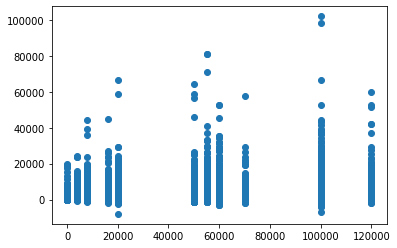
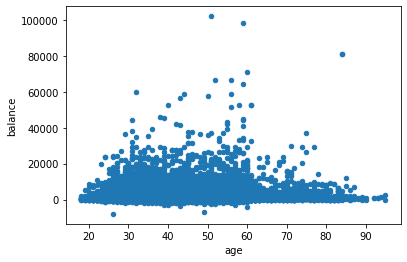
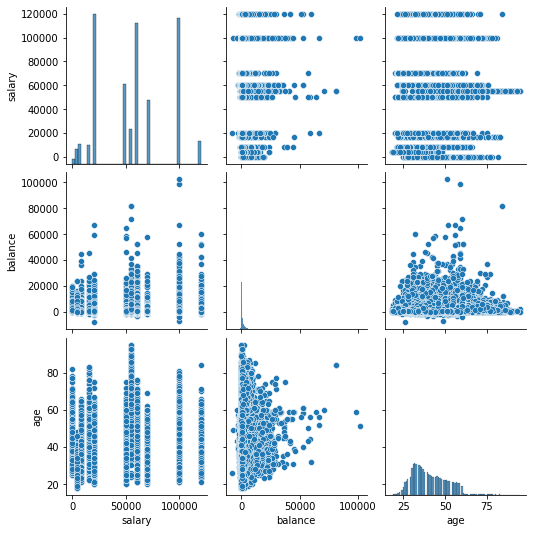
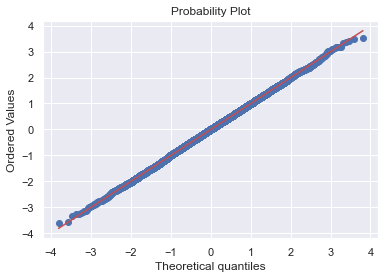
QQ-Plot¶
Es un método gráfico para el diagnóstico de diferencias entre la distribución de probabilidad de una población de la que se ha extraído una muestra aleatoria y una distribución usada para la comparación.
import scipy.stats as stats
iris = sns.load_dataset('iris')
rvs = stats.norm(loc=0, scale=1)
normal_sample = rvs.rvs(size=100000)
sns.set()
sns.distplot(normal_sample)
C:\ProgramData\Anaconda3\lib\site-packages\seaborn\distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
<AxesSubplot:ylabel='Density'>
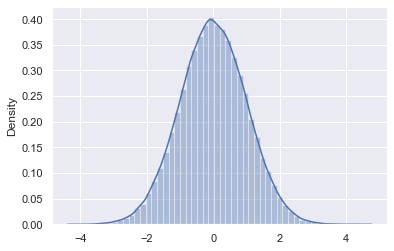
normal_sample = rvs.rvs(size=10000)
stats.probplot(normal_sample, dist="norm", plot=plt)
plt.show()
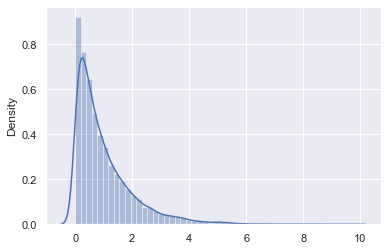
sns.distplot(stats.expon().rvs(size=10000))
C:\ProgramData\Anaconda3\lib\site-packages\seaborn\distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
<AxesSubplot:ylabel='Density'>
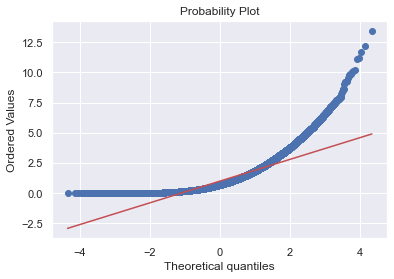
expon_rvs = stats.expon().rvs(size=100000)
normal_rvs = stats.norm().rvs(size=100000)
stats.probplot(x=expon_rvs, dist=stats.norm(), plot=plt)
((array([-4.34602155, -4.14724578, -4.03913009, ..., 4.03913009,
4.14724578, 4.34602155]),
array([2.16825700e-06, 1.57624189e-05, 2.93375619e-05, ...,
1.16652885e+01, 1.21702078e+01, 1.34591407e+01])),
(0.8996537488205563, 0.9969476608219366, 0.9033984542371438))
expon_rvs = stats.expon().rvs(size=100000)
stats.probplot(x=expon_rvs, dist="expon", plot=plt)
plt.show()
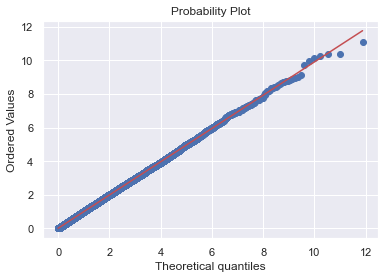
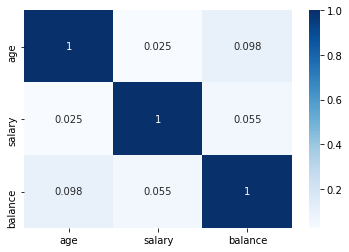
Matrices de correlación¶
Cuando queremos ver en un unico grafico las relaciones entre más de una variable de forma sintetica
db[['age','salary','balance']].corr()
| age | salary | balance | |
|---|---|---|---|
| age | 1.000000 | 0.024513 | 0.097710 |
| salary | 0.024513 | 1.000000 | 0.055489 |
| balance | 0.097710 | 0.055489 | 1.000000 |
sns.heatmap(db[['age','salary','balance']].corr(), annot=True, cmap = 'Blues')
plt.show()
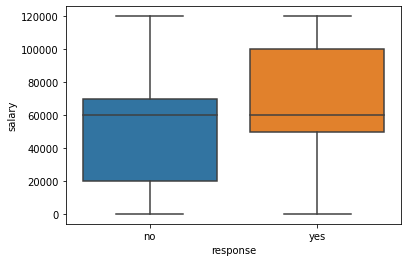
variables categoricas numericas¶
Normalmente se analizan con base en su media, mediana y un instrumento particularmente util es el boxplot.
Calculamolos a manita:
db.groupby('response')['salary'].mean()
response
no 56769.510482
yes 58780.510880
Name: salary, dtype: float64
db.groupby('response')['salary'].median()
response
no 60000
yes 60000
Name: salary, dtype: int64
Pareciera no haber grandes diferencias, pero analizando los boxplot descubrimos que:
sns.boxplot(x=db.response, y=db.salary)
plt.show()
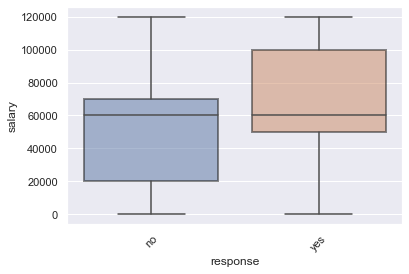
ax = sns.boxplot(x='response', y='salary', data=db)
plt.setp(ax.artists, alpha=.5, linewidth=2, edgecolor="k")
plt.xticks(rotation=45)
(array([0, 1]), [Text(0, 0, 'no'), Text(1, 0, 'yes')])
Analisis variables categoricas¶
Queremos analizar como diferentes varbles categoricas (como la educación) tienen impacto en la variable dependiente.. Para hacer eso necesitamos convertir Response en una variable binaria.
db['response_rate'] = np.where(db.response=='yes',1,0)
db.response_rate.value_counts()
0 39876
1 5285
Name: response_rate, dtype: int64
Analizando ahora como se distribuye frente distintos valores de la una variable categorica tendremos:
db.groupby('marital')['response_rate'].mean().plot.bar()
plt.show()
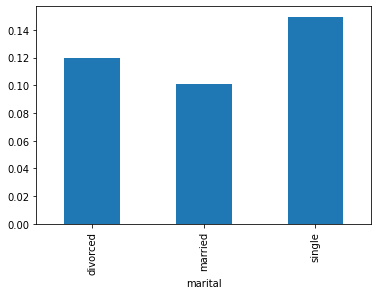
Analisis multivariado¶
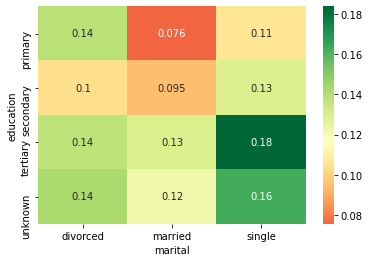
Antes tenemos crear una tabla pivot con en las columnas los diferentes status civiles:
result = pd.pivot_table(data=db, index='education', columns='marital',values='response_rate')
result
| marital | divorced | married | single |
|---|---|---|---|
| education | |||
| primary | 0.138852 | 0.075601 | 0.106808 |
| secondary | 0.103559 | 0.094650 | 0.129271 |
| tertiary | 0.137415 | 0.129835 | 0.183737 |
| unknown | 0.142012 | 0.122519 | 0.162879 |
Ahora como antes vamos a imprimir una mapa de calor.
sns.heatmap(result, annot=True, cmap = 'RdYlGn', center=0.117)
plt.show()
Apis y carca de datos¶
Podemos cargar los datos de local, commo hicimos antes en nuestro ejercicio, por medio de una url o con unas APIs.
#metodo URL
url = "http://climatedataapi.worldbank.org/climateweb/rest/v1/country/cru/tas/year/ROU.csv"
df = pd.read_csv(url)
df
Pero ahora sí pasamos a las APis
Blockquote Una API, o interfaz de programación de aplicaciones, es un servidor que puede utilizar para recuperar y enviar datos mediante código. Las API se utilizan con mayor frecuencia para recuperar datos.
¿Por que usar una API?
Los datos cambía rápido, y no tiene sentido estar generando un dataset y bajandolo cada munuto.
Necesitas acceder a sólo una parte de los datos
Hay una computación repetida involucrada
Podemos hacer diferentes acciones con las API:
GET
POST
PUT
DELETE
import requests
response = requests.get('https://google.com/')
print(response)
<Response [200]>

La libreria request tiene algunas funciones especificas:
print(response.status_code)
200
if response:
print('Request is successful.')
else:
print('Request returned an error.')
Request is successful.
El endpoint es una dirección, usuaklmente, hacía donde apunta nuestro pedido. Normalmente el nombre de esta dirección es autodescriptivo.
response = requests.get("http://api.open-notify.org/astros.json")
print(response.status_code)
200
pd.DataFrame(response.json()["people"])
| name | craft | |
|---|---|---|
| 0 | Mark Vande Hei | ISS |
| 1 | Oleg Novitskiy | ISS |
| 2 | Pyotr Dubrov | ISS |
| 3 | Thomas Pesquet | ISS |
| 4 | Megan McArthur | ISS |
| 5 | Shane Kimbrough | ISS |
| 6 | Akihiko Hoshide | ISS |
Muchas veces necesitamos una llave para poder acceder a los datos que requerimos. Igual hay un verdadero mercado y sitio especializados para esto.
Por medio de los encabezaados HTTPS se manejan algunas informaciones sobre las APIs
response = requests.get("https://api.thedogapi.com/v1/breeds/1")
response.headers
{'Content-Encoding': 'gzip', 'Content-Type': 'application/json; charset=utf-8', 'Date': 'Fri, 07 May 2021 12:19:43 GMT', 'Server': 'Apache/2.4.46 (Amazon)', 'Strict-Transport-Security': 'max-age=15552000; includeSubDomains', 'Vary': 'Origin,Accept-Encoding', 'X-Content-Type-Options': 'nosniff', 'X-DNS-Prefetch-Control': 'off', 'X-Download-Options': 'noopen', 'X-Frame-Options': 'SAMEORIGIN', 'X-Response-Time': '2ms', 'X-XSS-Protection': '1; mode=block', 'Content-Length': '265', 'Connection': 'keep-alive'}
Ya sabiendo que es un json, podemos acceder a el atravez de:
response.json()["name"]
'Affenpinscher'
endpoint = "https://www.googleapis.com/books/v1/volumes"
query = "la divina comedia"
params = {"q": query, "maxResults": 3}
response = requests.get(endpoint, params=params).json()
for book in response["items"]:
volume = book["volumeInfo"]
title = volume["title"]
published = volume["authors"]
print(f"{title} {published} ")
La Divina Comedia ['Dante Alighieri']
La divina comedia ['Dante Alghieri']
La Divina Comedia por Dante Alighieri ['Dante Alighieri']
response
{'kind': 'books#volumes',
'totalItems': 734,
'items': [{'kind': 'books#volume',
'id': 'WrPCDwAAQBAJ',
'etag': 'j6ynahmNPaE',
'selfLink': 'https://www.googleapis.com/books/v1/volumes/WrPCDwAAQBAJ',
'volumeInfo': {'title': 'La Divina Comedia',
'authors': ['Dante Alighieri'],
'publisher': 'Good Press',
'publishedDate': '2019-11-11',
'description': '"La Divina Comedia" de Dante Alighieri (traducido por Manuel Aranda y Sanjuan) de la Editorial Good Press. Good Press publica una gran variedad de títulos que abarca todos los géneros. Van desde los títulos clásicos famosos, novelas, textos documentales y crónicas de la vida real, hasta temas ignorados o por ser descubiertos de la literatura universal. Editorial Good Press divulga libros que son una lectura imprescindible. Cada publicación de Good Press ha sido corregida y formateada al detalle, para elevar en gran medida su facilidad de lectura en todos los equipos y programas de lectura electrónica. Nuestra meta es la producción de Libros electrónicos que sean versátiles y accesibles para el lector y para todos, en un formato digital de alta calidad.',
'industryIdentifiers': [{'type': 'OTHER',
'identifier': 'EAN:4057664122674'}],
'readingModes': {'text': True, 'image': True},
'pageCount': 941,
'printType': 'BOOK',
'categories': ['Fiction'],
'maturityRating': 'NOT_MATURE',
'allowAnonLogging': True,
'contentVersion': '1.5.5.0.preview.3',
'panelizationSummary': {'containsEpubBubbles': False,
'containsImageBubbles': False},
'imageLinks': {'smallThumbnail': 'http://books.google.com/books/content?id=WrPCDwAAQBAJ&printsec=frontcover&img=1&zoom=5&edge=curl&source=gbs_api',
'thumbnail': 'http://books.google.com/books/content?id=WrPCDwAAQBAJ&printsec=frontcover&img=1&zoom=1&edge=curl&source=gbs_api'},
'language': 'es',
'previewLink': 'http://books.google.com.mx/books?id=WrPCDwAAQBAJ&pg=PP1&dq=la+divina+comedia&hl=&cd=1&source=gbs_api',
'infoLink': 'https://play.google.com/store/books/details?id=WrPCDwAAQBAJ&source=gbs_api',
'canonicalVolumeLink': 'https://play.google.com/store/books/details?id=WrPCDwAAQBAJ'},
'saleInfo': {'country': 'MX',
'saleability': 'FOR_SALE',
'isEbook': True,
'listPrice': {'amount': 25, 'currencyCode': 'MXN'},
'retailPrice': {'amount': 25, 'currencyCode': 'MXN'},
'buyLink': 'https://play.google.com/store/books/details?id=WrPCDwAAQBAJ&rdid=book-WrPCDwAAQBAJ&rdot=1&source=gbs_api',
'offers': [{'finskyOfferType': 1,
'listPrice': {'amountInMicros': 25000000, 'currencyCode': 'MXN'},
'retailPrice': {'amountInMicros': 25000000, 'currencyCode': 'MXN'},
'giftable': True}]},
'accessInfo': {'country': 'MX',
'viewability': 'PARTIAL',
'embeddable': True,
'publicDomain': False,
'textToSpeechPermission': 'ALLOWED',
'epub': {'isAvailable': True},
'pdf': {'isAvailable': True},
'webReaderLink': 'http://play.google.com/books/reader?id=WrPCDwAAQBAJ&hl=&printsec=frontcover&source=gbs_api',
'accessViewStatus': 'SAMPLE',
'quoteSharingAllowed': False},
'searchInfo': {'textSnippet': '"La Divina Comedia" de Dante Alighieri (traducido por Manuel Aranda y Sanjuan) de la Editorial Good Press.'}},
{'kind': 'books#volume',
'id': 'wGPSDgAAQBAJ',
'etag': 'NOQVX9XaqiA',
'selfLink': 'https://www.googleapis.com/books/v1/volumes/wGPSDgAAQBAJ',
'volumeInfo': {'title': 'La divina comedia',
'subtitle': '',
'authors': ['Dante Alghieri'],
'publisher': 'NoBooks Editorial',
'publishedDate': '1976',
'readingModes': {'text': True, 'image': True},
'pageCount': 441,
'printType': 'BOOK',
'maturityRating': 'NOT_MATURE',
'allowAnonLogging': True,
'contentVersion': 'preview-1.0.0',
'panelizationSummary': {'containsEpubBubbles': False,
'containsImageBubbles': False},
'imageLinks': {'smallThumbnail': 'http://books.google.com/books/content?id=wGPSDgAAQBAJ&printsec=frontcover&img=1&zoom=5&edge=curl&source=gbs_api',
'thumbnail': 'http://books.google.com/books/content?id=wGPSDgAAQBAJ&printsec=frontcover&img=1&zoom=1&edge=curl&source=gbs_api'},
'language': 'es',
'previewLink': 'http://books.google.com.mx/books?id=wGPSDgAAQBAJ&printsec=frontcover&dq=la+divina+comedia&hl=&cd=2&source=gbs_api',
'infoLink': 'https://play.google.com/store/books/details?id=wGPSDgAAQBAJ&source=gbs_api',
'canonicalVolumeLink': 'https://play.google.com/store/books/details?id=wGPSDgAAQBAJ'},
'saleInfo': {'country': 'MX',
'saleability': 'FOR_SALE',
'isEbook': True,
'listPrice': {'amount': 28.84, 'currencyCode': 'MXN'},
'retailPrice': {'amount': 28.84, 'currencyCode': 'MXN'},
'buyLink': 'https://play.google.com/store/books/details?id=wGPSDgAAQBAJ&rdid=book-wGPSDgAAQBAJ&rdot=1&source=gbs_api',
'offers': [{'finskyOfferType': 1,
'listPrice': {'amountInMicros': 28840000, 'currencyCode': 'MXN'},
'retailPrice': {'amountInMicros': 28840000, 'currencyCode': 'MXN'},
'giftable': True}]},
'accessInfo': {'country': 'MX',
'viewability': 'PARTIAL',
'embeddable': True,
'publicDomain': False,
'textToSpeechPermission': 'ALLOWED',
'epub': {'isAvailable': True},
'pdf': {'isAvailable': True},
'webReaderLink': 'http://play.google.com/books/reader?id=wGPSDgAAQBAJ&hl=&printsec=frontcover&source=gbs_api',
'accessViewStatus': 'SAMPLE',
'quoteSharingAllowed': False}},
{'kind': 'books#volume',
'id': 'O0ESIQu9_7wC',
'etag': 'bzi0xAGR2sk',
'selfLink': 'https://www.googleapis.com/books/v1/volumes/O0ESIQu9_7wC',
'volumeInfo': {'title': 'La Divina Comedia por Dante Alighieri',
'subtitle': 'El Infierno',
'authors': ['Dante Alighieri'],
'publishedDate': '1870',
'industryIdentifiers': [{'type': 'OTHER',
'identifier': 'IBNF:CF005685501'}],
'readingModes': {'text': False, 'image': False},
'pageCount': 232,
'printType': 'BOOK',
'maturityRating': 'NOT_MATURE',
'allowAnonLogging': False,
'contentVersion': '0.2.1.0.preview.0',
'panelizationSummary': {'containsEpubBubbles': False,
'containsImageBubbles': False},
'imageLinks': {'smallThumbnail': 'http://books.google.com/books/content?id=O0ESIQu9_7wC&printsec=frontcover&img=1&zoom=5&source=gbs_api',
'thumbnail': 'http://books.google.com/books/content?id=O0ESIQu9_7wC&printsec=frontcover&img=1&zoom=1&source=gbs_api'},
'language': 'es',
'previewLink': 'http://books.google.com.mx/books?id=O0ESIQu9_7wC&q=la+divina+comedia&dq=la+divina+comedia&hl=&cd=3&source=gbs_api',
'infoLink': 'http://books.google.com.mx/books?id=O0ESIQu9_7wC&dq=la+divina+comedia&hl=&source=gbs_api',
'canonicalVolumeLink': 'https://books.google.com/books/about/La_Divina_Comedia_por_Dante_Alighieri.html?hl=&id=O0ESIQu9_7wC'},
'saleInfo': {'country': 'MX',
'saleability': 'NOT_FOR_SALE',
'isEbook': False},
'accessInfo': {'country': 'MX',
'viewability': 'NO_PAGES',
'embeddable': False,
'publicDomain': False,
'textToSpeechPermission': 'ALLOWED',
'epub': {'isAvailable': False},
'pdf': {'isAvailable': False},
'webReaderLink': 'http://play.google.com/books/reader?id=O0ESIQu9_7wC&hl=&printsec=frontcover&source=gbs_api',
'accessViewStatus': 'NONE',
'quoteSharingAllowed': False}}]}
Fuentes: