
Contenido
Pandas¶
¿A que nos sirve?¶
Con Pandas podemos manejar nuestros datos, modificandolos, transformandolos y analizandolos.
En particular podemos:
limpiar los datos presentes en un DataFrame
Visualizar los datos con la ayuda de Matplotlib
Almacenar los datos trasformados en otro archivo CSV
Panda está construido con base en Numpy y normalmente su output preferido es Scipy o Scikit-learn.
Antes que todo tendremos que importar los paquetes:
import pandas as pd
import numpy as np
Las dos componentes principales de Pandas son:
Series: es un vector vertical
DataFrame: es una Tabla (una matriz)
Las dos estructuras comparten muchas operaciones, que pueden ser hechas en ambos (como calcular la media).
Crear un diccionario¶
Tenemos diferentes maneras de construir un diccionario:
Por medio de un diccionario
data = {
'Inter': [3, 3, 0, 0],
'Juventus': [3, 2, 7, 106]
}
equipos = pd.DataFrame(data)
equipos
| Inter | Juventus | |
|---|---|---|
| 0 | 3 | 3 |
| 1 | 3 | 2 |
| 2 | 0 | 7 |
| 3 | 0 | 106 |
Cuando creamos un DataFrame de default nos dará un indice numerico, através del cual poemos acceder a las observaciones:
equipos.loc[0]
Inter 3
Juventus 3
Name: 0, dtype: int64
Pero resultaria mucho mas facil por medio de un indice «autoexplicativo», para asignarlo es suficiente especificarlo:
teams = pd.DataFrame(data, index=['Europa League', 'Champions', 'Ligas Robadas', 'Arbitros comprados'])
teams
| Inter | Juventus | |
|---|---|---|
| Europa League | 3 | 3 |
| Champions | 3 | 2 |
| Ligas Robadas | 0 | 7 |
| Arbitros comprados | 0 | 106 |
Podemos crearlo también a partir de listas:
list=[[1,2,3],[4,5,6]]
prueba= pd.DataFrame(list)
prueba
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 |
Podemos además importar un database:
df = pd.read_csv('C:\DAVE2\CIDE\Tesis\Base de Datos\Ageb_2010_DA_indice_de_rezago_social.csv')
df
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-6-d2a432c264d2> in <module>
----> 1 df = pd.read_csv('C:\DAVE2\CIDE\Tesis\Base de Datos\Ageb_2010_DA_indice_de_rezago_social.csv')
2
3 df
~/opt/anaconda3/lib/python3.8/site-packages/pandas/io/parsers.py in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
684 )
685
--> 686 return _read(filepath_or_buffer, kwds)
687
688
~/opt/anaconda3/lib/python3.8/site-packages/pandas/io/parsers.py in _read(filepath_or_buffer, kwds)
450
451 # Create the parser.
--> 452 parser = TextFileReader(fp_or_buf, **kwds)
453
454 if chunksize or iterator:
~/opt/anaconda3/lib/python3.8/site-packages/pandas/io/parsers.py in __init__(self, f, engine, **kwds)
944 self.options["has_index_names"] = kwds["has_index_names"]
945
--> 946 self._make_engine(self.engine)
947
948 def close(self):
~/opt/anaconda3/lib/python3.8/site-packages/pandas/io/parsers.py in _make_engine(self, engine)
1176 def _make_engine(self, engine="c"):
1177 if engine == "c":
-> 1178 self._engine = CParserWrapper(self.f, **self.options)
1179 else:
1180 if engine == "python":
~/opt/anaconda3/lib/python3.8/site-packages/pandas/io/parsers.py in __init__(self, src, **kwds)
2006 kwds["usecols"] = self.usecols
2007
-> 2008 self._reader = parsers.TextReader(src, **kwds)
2009 self.unnamed_cols = self._reader.unnamed_cols
2010
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader.__cinit__()
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source()
FileNotFoundError: [Errno 2] No such file or directory: 'C:\\DAVE2\\CIDE\\Tesis\\Base de Datos\\Ageb_2010_DA_indice_de_rezago_social.csv'
Para saber las dimensiones de nuestros DB es suficiente:
df.shape
(51034, 25)
for col in df.columns:
print(col)
cve_ent
ent
cve_mun
mun
cve_loc
loc
cve_ageb
folio_ageb
pob_tot
viv_par_hab
porc_pob_15_mas_basic_incom
porc_pob_15_24_noasiste
porc_pob_snservsal
porc_vivhacina
porc_vivsnsan
porc_vivsnlavadora
porc_vivsnrefri
porc_vivstelefono
porc_pob_15_mas_analfa
porc_pob6_14_noasiste
porc_vivpisotierra
porc_snaguaent
porc_vivsndren
porc_vivsnenergia
gdo_rezsoc
df.columns
Index(['cve_ent', 'ent', 'cve_mun', 'mun', 'cve_loc', 'loc', 'cve_ageb',
'folio_ageb', 'pob_tot', 'viv_par_hab', 'porc_pob_15_mas_basic_incom',
'porc_pob_15_24_noasiste', 'porc_pob_snservsal', 'porc_vivhacina',
'porc_vivsnsan', 'porc_vivsnlavadora', 'porc_vivsnrefri',
'porc_vivstelefono', 'porc_pob_15_mas_analfa', 'porc_pob6_14_noasiste',
'porc_vivpisotierra', 'porc_snaguaent', 'porc_vivsndren',
'porc_vivsnenergia', 'gdo_rezsoc'],
dtype='object')
df2 = pd.read_csv('C:\DAVE2\CIDE\Tesis\Base de Datos\Ageb_2010_DA_indice_de_rezago_social.csv', index_col=0)
df2
| ent | cve_mun | mun | cve_loc | loc | cve_ageb | folio_ageb | pob_tot | viv_par_hab | porc_pob_15_mas_basic_incom | ... | porc_vivsnlavadora | porc_vivsnrefri | porc_vivstelefono | porc_pob_15_mas_analfa | porc_pob6_14_noasiste | porc_vivpisotierra | porc_snaguaent | porc_vivsndren | porc_vivsnenergia | gdo_rezsoc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cve_ent | |||||||||||||||||||||
| 1 | Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0229 | 0100100010229 | 410 | 104 | 35.1 | ... | 18.3 | 9.6 | 39.4 | 4.7 | 3.4 | 2.9 | 0.0 | 0.0 | 1.0 | Bajo |
| 1 | Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0233 | 0100100010233 | 1536 | 421 | 35.5 | ... | 21.9 | 9.3 | 40.9 | 3.4 | 7.1 | 1.7 | 0.5 | 1.0 | 0.2 | Bajo |
| 1 | Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0286 | 0100100010286 | 3469 | 986 | 16.0 | ... | 6.8 | 1.2 | 14.9 | 1.0 | 1.8 | 2.6 | 0.4 | 0.0 | 0.0 | Bajo |
| 1 | Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0290 | 0100100010290 | 1884 | 504 | 18.5 | ... | 4.6 | 0.6 | 13.5 | 0.9 | 1.8 | 0.2 | 0.0 | 0.0 | 0.0 | Bajo |
| 1 | Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0303 | 0100100010303 | 2397 | 625 | 30.3 | ... | 8.6 | 3.0 | 25.9 | 1.9 | 3.8 | 0.2 | 0.2 | 0.2 | 0.0 | Bajo |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 32 | Zacatecas | 57 | Trancoso | 1 | TRANCOSO | 0412 | 3205700010412 | 12 | 2 | ND | ... | ND | ND | ND | ND | ND | ND | ND | ND | ND | Alto |
| 32 | Zacatecas | 57 | Trancoso | 1 | TRANCOSO | 0431 | 3205700010431 | 14 | 3 | 42.9 | ... | 33.3 | 0.0 | 100.0 | 0.0 | 0.0 | 0.0 | 66.7 | 0.0 | 0.0 | Alto |
| 32 | Zacatecas | 58 | Santa Mar�a de la Paz | 1 | SANTA MAR�A DE LA PAZ | 0015 | 3205800010015 | 651 | 175 | 54.6 | ... | 19.4 | 12.0 | 40.6 | 7.0 | 1.0 | 1.1 | 3.4 | 0.0 | 1.1 | Bajo |
| 32 | Zacatecas | 58 | Santa Mar�a de la Paz | 1 | SANTA MAR�A DE LA PAZ | 002A | 320580001002A | 945 | 251 | 55.8 | ... | 18.7 | 14.3 | 37.1 | 6.8 | 4.5 | 1.6 | 1.6 | 1.2 | 1.6 | Bajo |
| 32 | Zacatecas | 58 | Santa Mar�a de la Paz | 1 | SANTA MAR�A DE LA PAZ | 0104 | 3205800010104 | 86 | 25 | 42.9 | ... | 52.0 | 32.0 | 100.0 | 6.1 | 0.0 | 4.0 | 0.0 | 0.0 | 0.0 | Medio |
51034 rows × 24 columns
Con pd.read_json(“purchases.json”) podemos leer file json, de igual forma podemos también leer file sql.
Podemos cambiar el indice escogido
df2.set_index('ent')
| cve_mun | mun | cve_loc | loc | cve_ageb | folio_ageb | pob_tot | viv_par_hab | porc_pob_15_mas_basic_incom | porc_pob_15_24_noasiste | ... | porc_vivsnlavadora | porc_vivsnrefri | porc_vivstelefono | porc_pob_15_mas_analfa | porc_pob6_14_noasiste | porc_vivpisotierra | porc_snaguaent | porc_vivsndren | porc_vivsnenergia | gdo_rezsoc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ent | |||||||||||||||||||||
| Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0229 | 0100100010229 | 410 | 104 | 35.1 | 52.5 | ... | 18.3 | 9.6 | 39.4 | 4.7 | 3.4 | 2.9 | 0.0 | 0.0 | 1.0 | Bajo |
| Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0233 | 0100100010233 | 1536 | 421 | 35.5 | 57.7 | ... | 21.9 | 9.3 | 40.9 | 3.4 | 7.1 | 1.7 | 0.5 | 1.0 | 0.2 | Bajo |
| Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0286 | 0100100010286 | 3469 | 986 | 16.0 | 32.4 | ... | 6.8 | 1.2 | 14.9 | 1.0 | 1.8 | 2.6 | 0.4 | 0.0 | 0.0 | Bajo |
| Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0290 | 0100100010290 | 1884 | 504 | 18.5 | 31.8 | ... | 4.6 | 0.6 | 13.5 | 0.9 | 1.8 | 0.2 | 0.0 | 0.0 | 0.0 | Bajo |
| Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0303 | 0100100010303 | 2397 | 625 | 30.3 | 42.7 | ... | 8.6 | 3.0 | 25.9 | 1.9 | 3.8 | 0.2 | 0.2 | 0.2 | 0.0 | Bajo |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Zacatecas | 57 | Trancoso | 1 | TRANCOSO | 0412 | 3205700010412 | 12 | 2 | ND | ND | ... | ND | ND | ND | ND | ND | ND | ND | ND | ND | Alto |
| Zacatecas | 57 | Trancoso | 1 | TRANCOSO | 0431 | 3205700010431 | 14 | 3 | 42.9 | 100.0 | ... | 33.3 | 0.0 | 100.0 | 0.0 | 0.0 | 0.0 | 66.7 | 0.0 | 0.0 | Alto |
| Zacatecas | 58 | Santa Mar�a de la Paz | 1 | SANTA MAR�A DE LA PAZ | 0015 | 3205800010015 | 651 | 175 | 54.6 | 59.0 | ... | 19.4 | 12.0 | 40.6 | 7.0 | 1.0 | 1.1 | 3.4 | 0.0 | 1.1 | Bajo |
| Zacatecas | 58 | Santa Mar�a de la Paz | 1 | SANTA MAR�A DE LA PAZ | 002A | 320580001002A | 945 | 251 | 55.8 | 56.6 | ... | 18.7 | 14.3 | 37.1 | 6.8 | 4.5 | 1.6 | 1.6 | 1.2 | 1.6 | Bajo |
| Zacatecas | 58 | Santa Mar�a de la Paz | 1 | SANTA MAR�A DE LA PAZ | 0104 | 3205800010104 | 86 | 25 | 42.9 | 66.7 | ... | 52.0 | 32.0 | 100.0 | 6.1 | 0.0 | 4.0 | 0.0 | 0.0 | 0.0 | Medio |
51034 rows × 23 columns
Podemos luego guardar los resultados en un archivo CSV:
df2.to_csv('nueva_base.csv')
Primero de todo necesitamos usualmente analizar los primeros datos de nuestro DB:
df.head(5)
| cve_ent | ent | cve_mun | mun | cve_loc | loc | cve_ageb | folio_ageb | pob_tot | viv_par_hab | ... | porc_vivsnlavadora | porc_vivsnrefri | porc_vivstelefono | porc_pob_15_mas_analfa | porc_pob6_14_noasiste | porc_vivpisotierra | porc_snaguaent | porc_vivsndren | porc_vivsnenergia | gdo_rezsoc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0229 | 0100100010229 | 410 | 104 | ... | 18.3 | 9.6 | 39.4 | 4.7 | 3.4 | 2.9 | 0.0 | 0.0 | 1.0 | Bajo |
| 1 | 1 | Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0233 | 0100100010233 | 1536 | 421 | ... | 21.9 | 9.3 | 40.9 | 3.4 | 7.1 | 1.7 | 0.5 | 1.0 | 0.2 | Bajo |
| 2 | 1 | Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0286 | 0100100010286 | 3469 | 986 | ... | 6.8 | 1.2 | 14.9 | 1.0 | 1.8 | 2.6 | 0.4 | 0.0 | 0.0 | Bajo |
| 3 | 1 | Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0290 | 0100100010290 | 1884 | 504 | ... | 4.6 | 0.6 | 13.5 | 0.9 | 1.8 | 0.2 | 0.0 | 0.0 | 0.0 | Bajo |
| 4 | 1 | Aguascalientes | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0303 | 0100100010303 | 2397 | 625 | ... | 8.6 | 3.0 | 25.9 | 1.9 | 3.8 | 0.2 | 0.2 | 0.2 | 0.0 | Bajo |
5 rows × 25 columns
df.tail(7)
| cve_ent | ent | cve_mun | mun | cve_loc | loc | cve_ageb | folio_ageb | pob_tot | viv_par_hab | ... | porc_vivsnlavadora | porc_vivsnrefri | porc_vivstelefono | porc_pob_15_mas_analfa | porc_pob6_14_noasiste | porc_vivpisotierra | porc_snaguaent | porc_vivsndren | porc_vivsnenergia | gdo_rezsoc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 51027 | 32 | Zacatecas | 57 | Trancoso | 1 | TRANCOSO | 0361 | 3205700010361 | 20 | 5 | ... | 20.0 | 40.0 | 100.0 | 20.0 | 14.3 | 0.0 | 0.0 | 20.0 | 20.0 | Alto |
| 51028 | 32 | Zacatecas | 57 | Trancoso | 1 | TRANCOSO | 0408 | 3205700010408 | 143 | 25 | ... | 52.0 | 56.0 | 96.0 | 18.3 | 8.1 | 0.0 | 28.0 | 48.0 | 8.0 | Medio |
| 51029 | 32 | Zacatecas | 57 | Trancoso | 1 | TRANCOSO | 0412 | 3205700010412 | 12 | 2 | ... | ND | ND | ND | ND | ND | ND | ND | ND | ND | Alto |
| 51030 | 32 | Zacatecas | 57 | Trancoso | 1 | TRANCOSO | 0431 | 3205700010431 | 14 | 3 | ... | 33.3 | 0.0 | 100.0 | 0.0 | 0.0 | 0.0 | 66.7 | 0.0 | 0.0 | Alto |
| 51031 | 32 | Zacatecas | 58 | Santa Mar�a de la Paz | 1 | SANTA MAR�A DE LA PAZ | 0015 | 3205800010015 | 651 | 175 | ... | 19.4 | 12.0 | 40.6 | 7.0 | 1.0 | 1.1 | 3.4 | 0.0 | 1.1 | Bajo |
| 51032 | 32 | Zacatecas | 58 | Santa Mar�a de la Paz | 1 | SANTA MAR�A DE LA PAZ | 002A | 320580001002A | 945 | 251 | ... | 18.7 | 14.3 | 37.1 | 6.8 | 4.5 | 1.6 | 1.6 | 1.2 | 1.6 | Bajo |
| 51033 | 32 | Zacatecas | 58 | Santa Mar�a de la Paz | 1 | SANTA MAR�A DE LA PAZ | 0104 | 3205800010104 | 86 | 25 | ... | 52.0 | 32.0 | 100.0 | 6.1 | 0.0 | 4.0 | 0.0 | 0.0 | 0.0 | Medio |
7 rows × 25 columns
df3 = pd.read_csv('C:\DAVE2\CIDE\Tesis\Base de Datos\Ageb_2010_DA_indice_de_rezago_social.csv', index_col='ent')
df3.head(5)
| cve_ent | cve_mun | mun | cve_loc | loc | cve_ageb | folio_ageb | pob_tot | viv_par_hab | porc_pob_15_mas_basic_incom | ... | porc_vivsnlavadora | porc_vivsnrefri | porc_vivstelefono | porc_pob_15_mas_analfa | porc_pob6_14_noasiste | porc_vivpisotierra | porc_snaguaent | porc_vivsndren | porc_vivsnenergia | gdo_rezsoc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ent | |||||||||||||||||||||
| Aguascalientes | 1 | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0229 | 0100100010229 | 410 | 104 | 35.1 | ... | 18.3 | 9.6 | 39.4 | 4.7 | 3.4 | 2.9 | 0.0 | 0.0 | 1.0 | Bajo |
| Aguascalientes | 1 | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0233 | 0100100010233 | 1536 | 421 | 35.5 | ... | 21.9 | 9.3 | 40.9 | 3.4 | 7.1 | 1.7 | 0.5 | 1.0 | 0.2 | Bajo |
| Aguascalientes | 1 | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0286 | 0100100010286 | 3469 | 986 | 16.0 | ... | 6.8 | 1.2 | 14.9 | 1.0 | 1.8 | 2.6 | 0.4 | 0.0 | 0.0 | Bajo |
| Aguascalientes | 1 | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0290 | 0100100010290 | 1884 | 504 | 18.5 | ... | 4.6 | 0.6 | 13.5 | 0.9 | 1.8 | 0.2 | 0.0 | 0.0 | 0.0 | Bajo |
| Aguascalientes | 1 | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0303 | 0100100010303 | 2397 | 625 | 30.3 | ... | 8.6 | 3.0 | 25.9 | 1.9 | 3.8 | 0.2 | 0.2 | 0.2 | 0.0 | Bajo |
5 rows × 24 columns
Podemos obtener información con respecto a nuestro DB:
df3.info()
<class 'pandas.core.frame.DataFrame'>
Index: 51034 entries, Aguascalientes to Zacatecas
Data columns (total 24 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 cve_ent 51034 non-null int64
1 cve_mun 51034 non-null int64
2 mun 51034 non-null object
3 cve_loc 51034 non-null int64
4 loc 51034 non-null object
5 cve_ageb 51034 non-null object
6 folio_ageb 51034 non-null object
7 pob_tot 51034 non-null int64
8 viv_par_hab 51034 non-null int64
9 porc_pob_15_mas_basic_incom 51034 non-null object
10 porc_pob_15_24_noasiste 51034 non-null object
11 porc_pob_snservsal 51034 non-null object
12 porc_vivhacina 51034 non-null object
13 porc_vivsnsan 51034 non-null object
14 porc_vivsnlavadora 51034 non-null object
15 porc_vivsnrefri 51034 non-null object
16 porc_vivstelefono 51034 non-null object
17 porc_pob_15_mas_analfa 51034 non-null object
18 porc_pob6_14_noasiste 51034 non-null object
19 porc_vivpisotierra 51034 non-null object
20 porc_snaguaent 51034 non-null object
21 porc_vivsndren 51034 non-null object
22 porc_vivsnenergia 51034 non-null object
23 gdo_rezsoc 51034 non-null object
dtypes: int64(5), object(19)
memory usage: 9.7+ MB
Podemos mergear dos DB verticalmente con la siguiente función:
temp_df = df3.append(df3)
temp_df.shape
(102068, 24)
Para eliminar duplicados será suficiente hacer:
temp_df = temp_df.drop_duplicates()
temp_df.shape
(51034, 24)
Siempre estaremos regresando una copia del DB, si queremos modificarlo directamente tendremos que ocupar la funcion inplace
temp_df.shape
(51034, 24)
temp_df2 = df3.append(df3)
temp_df2.drop_duplicates()
temp_df2.shape
(102068, 24)
temp_df2 = df3.append(df3)
temp_df2.drop_duplicates(keep=False, inplace=True)
#temp_df2.shape
(0, 24)
Keep especifica cual de los duplicados considerar:
false dropea todo
first mantiene el primero
last mantiene el ultimo
Para ver los nombres de las columnas podemos utilizar la siguiente función:
df3.columns
Index(['cve_ent', 'cve_mun', 'mun', 'cve_loc', 'loc', 'cve_ageb', 'folio_ageb',
'pob_tot', 'viv_par_hab', 'porc_pob_15_mas_basic_incom',
'porc_pob_15_24_noasiste', 'porc_pob_snservsal', 'porc_vivhacina',
'porc_vivsnsan', 'porc_vivsnlavadora', 'porc_vivsnrefri',
'porc_vivstelefono', 'porc_pob_15_mas_analfa', 'porc_pob6_14_noasiste',
'porc_vivpisotierra', 'porc_snaguaent', 'porc_vivsndren',
'porc_vivsnenergia', 'gdo_rezsoc'],
dtype='object')
Para cambiar el nombre de una columna haremos lo siguiente:
df3.rename(columns={
'mun': 'municipio',
'pob_tot': 'poblacion total'
}, inplace=True)
df3.head()
| cve_ent | cve_mun | municipio | cve_loc | loc | cve_ageb | folio_ageb | poblacion total | viv_par_hab | porc_pob_15_mas_basic_incom | ... | porc_vivsnlavadora | porc_vivsnrefri | porc_vivstelefono | porc_pob_15_mas_analfa | porc_pob6_14_noasiste | porc_vivpisotierra | porc_snaguaent | porc_vivsndren | porc_vivsnenergia | gdo_rezsoc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ent | |||||||||||||||||||||
| Aguascalientes | 1 | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0229 | 0100100010229 | 410 | 104 | 35.1 | ... | 18.3 | 9.6 | 39.4 | 4.7 | 3.4 | 2.9 | 0.0 | 0.0 | 1.0 | Bajo |
| Aguascalientes | 1 | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0233 | 0100100010233 | 1536 | 421 | 35.5 | ... | 21.9 | 9.3 | 40.9 | 3.4 | 7.1 | 1.7 | 0.5 | 1.0 | 0.2 | Bajo |
| Aguascalientes | 1 | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0286 | 0100100010286 | 3469 | 986 | 16.0 | ... | 6.8 | 1.2 | 14.9 | 1.0 | 1.8 | 2.6 | 0.4 | 0.0 | 0.0 | Bajo |
| Aguascalientes | 1 | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0290 | 0100100010290 | 1884 | 504 | 18.5 | ... | 4.6 | 0.6 | 13.5 | 0.9 | 1.8 | 0.2 | 0.0 | 0.0 | 0.0 | Bajo |
| Aguascalientes | 1 | 1 | Aguascalientes | 1 | AGUASCALIENTES | 0303 | 0100100010303 | 2397 | 625 | 30.3 | ... | 8.6 | 3.0 | 25.9 | 1.9 | 3.8 | 0.2 | 0.2 | 0.2 | 0.0 | Bajo |
5 rows × 24 columns
df3.columns
Podemos tambien asignarlos por medio de una lista:
teams.columns=[col.lower() for col in teams]
teams.columns
Index(['inter', 'juventus'], dtype='object')
teams.columns=['Internazionale','Rubentus']
teams.head()
| Internazionale | Rubentus | |
|---|---|---|
| Europa League | 3 | 3 |
| Champions | 3 | 2 |
| Ligas Robadas | 0 | 7 |
| Arbitros comprados | 0 | 106 |
Es buena norma utilizar caracteres minuscolos, quitar espacio y utilizar underscores y evitar accentos.
Los valores faltantes¶
Cuando analizamos unas bases, en particular las del INEGI ;) , tenemos que estar cuidado con el manejo de los valores faltantes. Esto podrán aparecernos como np.nan (Numpy) o como None (Python). A veces el manejo de los dos diferentes tipos puede ser distinto.
cuando tenemos valores mancantes tenemos distintas manera con que resolver el problema:
Eliminar la observación
Remplazar el valor nulo por medio de una imputación
db=pd.read_csv('C:\DAVE2\CIDE\Tesis\Base de Datos\Ageb_2010_DA_indice_de_rezago_social2.csv')
db.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 51034 entries, 0 to 51033
Data columns (total 25 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 cve_ent 51034 non-null int64
1 ent 51034 non-null object
2 cve_mun 51025 non-null float64
3 mun 51025 non-null object
4 cve_loc 51025 non-null float64
5 loc 51025 non-null object
6 cve_ageb 51021 non-null object
7 folio_ageb 51021 non-null object
8 pob_tot 51021 non-null float64
9 viv_par_hab 51013 non-null float64
10 porc_pob_15_mas_basic_incom 51013 non-null object
11 porc_pob_15_24_noasiste 51013 non-null object
12 porc_pob_snservsal 51004 non-null object
13 porc_vivhacina 51004 non-null object
14 porc_vivsnsan 51008 non-null object
15 porc_vivsnlavadora 51008 non-null object
16 porc_vivsnrefri 51008 non-null object
17 porc_vivstelefono 51017 non-null object
18 porc_pob_15_mas_analfa 51017 non-null object
19 porc_pob6_14_noasiste 51017 non-null object
20 porc_vivpisotierra 51023 non-null object
21 porc_snaguaent 51023 non-null object
22 porc_vivsndren 51023 non-null object
23 porc_vivsnenergia 51023 non-null object
24 gdo_rezsoc 51034 non-null object
dtypes: float64(4), int64(1), object(20)
memory usage: 9.7+ MB
db.isnull()
| cve_ent | ent | cve_mun | mun | cve_loc | loc | cve_ageb | folio_ageb | pob_tot | viv_par_hab | ... | porc_vivsnlavadora | porc_vivsnrefri | porc_vivstelefono | porc_pob_15_mas_analfa | porc_pob6_14_noasiste | porc_vivpisotierra | porc_snaguaent | porc_vivsndren | porc_vivsnenergia | gdo_rezsoc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 1 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False | False | False | False | True | ... | True | True | True | True | True | False | False | False | False | False |
| 3 | False | False | False | False | False | False | False | False | False | True | ... | True | True | True | True | True | False | False | False | False | False |
| 4 | False | False | False | False | False | False | False | False | False | True | ... | True | True | True | True | True | False | False | False | False | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 51029 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 51030 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 51031 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 51032 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 51033 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
51034 rows × 25 columns
db.shape
(51034, 25)
db.isnull().sum()
cve_ent 0
ent 0
cve_mun 9
mun 9
cve_loc 9
loc 9
cve_ageb 13
folio_ageb 13
pob_tot 13
viv_par_hab 21
porc_pob_15_mas_basic_incom 21
porc_pob_15_24_noasiste 21
porc_pob_snservsal 30
porc_vivhacina 30
porc_vivsnsan 26
porc_vivsnlavadora 26
porc_vivsnrefri 26
porc_vivstelefono 17
porc_pob_15_mas_analfa 17
porc_pob6_14_noasiste 17
porc_vivpisotierra 11
porc_snaguaent 11
porc_vivsndren 11
porc_vivsnenergia 11
gdo_rezsoc 0
dtype: int64
Si queremos eliminar las observaciones con por lo menos un NaN utilizaremos la siguiente expresión:
db2=db.dropna()
db2.shape
(50993, 25)
Podemos tambié escoger de eliminar las columnas con valores nulos
db3=db.dropna(axis=1)
db3.shape
(51034, 3)
Para poder imputar nuestro valores mancantes podemos hacer lo siguiente:
cvep=db['cve_mun']
cvep_mean=cvep.mean()
cvep.fillna(cvep_mean, inplace=True)
db.isnull().sum()
cve_ent 0
ent 0
cve_mun 0
mun 9
cve_loc 9
loc 9
cve_ageb 13
folio_ageb 13
pob_tot 13
viv_par_hab 21
porc_pob_15_mas_basic_incom 21
porc_pob_15_24_noasiste 21
porc_pob_snservsal 30
porc_vivhacina 30
porc_vivsnsan 26
porc_vivsnlavadora 26
porc_vivsnrefri 26
porc_vivstelefono 17
porc_pob_15_mas_analfa 17
porc_pob6_14_noasiste 17
porc_vivpisotierra 11
porc_snaguaent 11
porc_vivsndren 11
porc_vivsnenergia 11
gdo_rezsoc 0
dtype: int64
Entender el DB¶
Para mejor comprender la estructura dle DB podmeos utilizar :
db.describe()
| cve_ent | cve_mun | cve_loc | pob_tot | viv_par_hab | |
|---|---|---|---|---|---|
| count | 51034.000000 | 51034.000000 | 51025.000000 | 51021.000000 | 51013.000000 |
| mean | 16.870263 | 51.984478 | 21.763822 | 1703.227534 | 434.833297 |
| std | 8.306986 | 71.438801 | 110.321950 | 1726.229945 | 441.300656 |
| min | 1.000000 | 1.000000 | 1.000000 | 2.000000 | 1.000000 |
| 25% | 11.000000 | 12.000000 | 1.000000 | 294.000000 | 74.000000 |
| 50% | 15.000000 | 31.000000 | 1.000000 | 1268.000000 | 325.000000 |
| 75% | 24.000000 | 64.000000 | 1.000000 | 2555.000000 | 653.000000 |
| max | 32.000000 | 570.000000 | 4705.000000 | 22876.000000 | 6160.000000 |
df['gdo_rezsoc'].describe()
count 51034
unique 3
top Bajo
freq 33024
Name: gdo_rezsoc, dtype: object
Ahora bien para contar los valores en una columna haremos:
db['gdo_rezsoc'].value_counts().head(10)
Bajo 33024
Medio 12305
Alto 5705
Name: gdo_rezsoc, dtype: int64
Podemos también analizar la correlacion entre variables, por medio de una matriz de correlación. Puede ser utili particularmente cuando queremos analizar una variable resultado con respecto a alguna potencial explicativa:
db.corr()
| cve_ent | cve_mun | cve_loc | pob_tot | viv_par_hab | |
|---|---|---|---|---|---|
| cve_ent | 1.000000 | 0.193240 | -0.079972 | -0.089065 | -0.089841 |
| cve_mun | 0.193240 | 1.000000 | -0.052669 | -0.054085 | -0.063511 |
| cve_loc | -0.079972 | -0.052669 | 1.000000 | -0.029778 | -0.029908 |
| pob_tot | -0.089065 | -0.054085 | -0.029778 | 1.000000 | 0.986179 |
| viv_par_hab | -0.089841 | -0.063511 | -0.029908 | 0.986179 | 1.000000 |
Seleccionar y «slice»¶
Para seleccionar una columna podremos:
pob_col=df['pob_tot']
type(pob_col)
pandas.core.series.Series
Si queremos extraer una columna como dataframe tendremos que:
pob_col2=df[['pob_tot']]
type(pob_col2)
pandas.core.frame.DataFrame
Siendo una lista podemos extrer todas las olumnas que queremos:
sub=df[['pob_tot','cve_ent','ent']]
sub.head(5)
| pob_tot | cve_ent | ent | |
|---|---|---|---|
| 0 | 410 | 1 | Aguascalientes |
| 1 | 1536 | 1 | Aguascalientes |
| 2 | 3469 | 1 | Aguascalientes |
| 3 | 1884 | 1 | Aguascalientes |
| 4 | 2397 | 1 | Aguascalientes |
Para seleccionar los renglones tenemos dos opciones:
loc
iloc
prueba = teams.loc['Champions']
prueba
Internazionale 3
Rubentus 2
Name: Champions, dtype: int64
teams
| Internazionale | Rubentus | |
|---|---|---|
| Europa League | 3 | 3 |
| Champions | 3 | 2 |
| Ligas Robadas | 0 | 7 |
| Arbitros comprados | 0 | 106 |
prueba2=teams.iloc[2,1]
prueba2
7
Podemos de igual manera seleccionar más de un renglon:
prueba3=teams.iloc[0:3]
prueba3
| Internazionale | Rubentus | |
|---|---|---|
| Europa League | 3 | 3 |
| Champions | 3 | 2 |
| Ligas Robadas | 0 | 7 |
prueba4=teams.loc['Europa League':'Ligas Robadas']
prueba4
| Internazionale | Rubentus | |
|---|---|---|
| Europa League | 3 | 3 |
| Champions | 3 | 2 |
| Ligas Robadas | 0 | 7 |
Podemos también seleccionar con base en un criterio:
condition = (df['ent'] == 'Guerrero')
condition.head()
condition.sum()
2000
df[df['ent'] == 'Guerrero']
| cve_ent | ent | cve_mun | mun | cve_loc | loc | cve_ageb | folio_ageb | pob_tot | viv_par_hab | ... | porc_vivsnlavadora | porc_vivsnrefri | porc_vivstelefono | porc_pob_15_mas_analfa | porc_pob6_14_noasiste | porc_vivpisotierra | porc_snaguaent | porc_vivsndren | porc_vivsnenergia | gdo_rezsoc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 14944 | 12 | Guerrero | 1 | Acapulco de Ju�rez | 1 | ACAPULCO DE JU�REZ | 0034 | 1200100010034 | 4049 | 982 | ... | 41.4 | 9.1 | 46.0 | 7.1 | 4.3 | 6.5 | 2.4 | 0.6 | 0.2 | Bajo |
| 14945 | 12 | Guerrero | 1 | Acapulco de Ju�rez | 1 | ACAPULCO DE JU�REZ | 0049 | 1200100010049 | 4275 | 1017 | ... | 40.8 | 9.6 | 44.4 | 8.4 | 3.9 | 5.3 | 0.9 | 0.0 | 0.0 | Bajo |
| 14946 | 12 | Guerrero | 1 | Acapulco de Ju�rez | 1 | ACAPULCO DE JU�REZ | 0091 | 1200100010091 | 3080 | 914 | ... | 22.5 | 7.9 | 37.9 | 1.4 | 1.9 | 6.5 | 4.7 | 2.6 | 0.3 | Bajo |
| 14947 | 12 | Guerrero | 1 | Acapulco de Ju�rez | 1 | ACAPULCO DE JU�REZ | 0104 | 1200100010104 | 2299 | 610 | ... | 31.6 | 5.2 | 38.9 | 5.8 | 1.4 | 1.5 | 1.5 | 0.0 | 0.0 | Bajo |
| 14948 | 12 | Guerrero | 1 | Acapulco de Ju�rez | 1 | ACAPULCO DE JU�REZ | 0231 | 1200100010231 | 3609 | 1022 | ... | 29.5 | 5.9 | 35.3 | 1.6 | 4.0 | 1.5 | 1.3 | 0.0 | 0.5 | Bajo |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 16939 | 12 | Guerrero | 80 | Juchit�n | 1 | JUCHIT�N | 0127 | 1208000010127 | 53 | 11 | ... | 36.4 | 27.3 | 90.9 | 51.6 | 0.0 | 18.2 | 27.3 | 36.4 | 9.1 | Alto |
| 16940 | 12 | Guerrero | 81 | Iliatenco | 1 | ILIATENCO | 0016 | 1208100010016 | 1492 | 294 | ... | 81.0 | 26.2 | 81.0 | 11.1 | 1.0 | 15.0 | 22.4 | 13.6 | 3.4 | Medio |
| 16941 | 12 | Guerrero | 81 | Iliatenco | 1 | ILIATENCO | 004A | 120810001004A | 61 | 13 | ... | 84.6 | 38.5 | 92.3 | 14.3 | 0.0 | 15.4 | 23.1 | 53.8 | 15.4 | Alto |
| 16942 | 12 | Guerrero | 81 | Iliatenco | 1 | ILIATENCO | 0054 | 1208100010054 | 11 | 1 | ... | ND | ND | ND | ND | ND | ND | ND | ND | ND | Alto |
| 16943 | 12 | Guerrero | 81 | Iliatenco | 1 | ILIATENCO | 0069 | 1208100010069 | 143 | 26 | ... | 84.6 | 34.6 | 69.2 | 12.5 | 2.3 | 7.7 | 42.3 | 3.8 | 0.0 | Medio |
2000 rows × 25 columns
df[df['pob_tot'] >= 20000].head(3)
| cve_ent | ent | cve_mun | mun | cve_loc | loc | cve_ageb | folio_ageb | pob_tot | viv_par_hab | ... | porc_vivsnlavadora | porc_vivsnrefri | porc_vivstelefono | porc_pob_15_mas_analfa | porc_pob6_14_noasiste | porc_vivpisotierra | porc_snaguaent | porc_vivsndren | porc_vivsnenergia | gdo_rezsoc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 23295 | 15 | M�xico | 39 | Ixtapaluca | 1 | IXTAPALUCA | 075A | 150390001075A | 22876 | 6160 | ... | 13.6 | 4.3 | 32.3 | 0.7 | 1.7 | 1.1 | 0.3 | 0.0 | 0.0 | Bajo |
| 24459 | 15 | M�xico | 81 | Tec�mac | 19 | OJO DE AGUA | 1130 | 1508100191130 | 20183 | 5929 | ... | 15.2 | 4.6 | 41.2 | 0.3 | 1.7 | 0.6 | 0.1 | 0.0 | 0.0 | Bajo |
2 rows × 25 columns
df[(df['pob_tot'] >= 20000) & (df['viv_par_hab'] >= 6000)].head(3)
| cve_ent | ent | cve_mun | mun | cve_loc | loc | cve_ageb | folio_ageb | pob_tot | viv_par_hab | ... | porc_vivsnlavadora | porc_vivsnrefri | porc_vivstelefono | porc_pob_15_mas_analfa | porc_pob6_14_noasiste | porc_vivpisotierra | porc_snaguaent | porc_vivsndren | porc_vivsnenergia | gdo_rezsoc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 23295 | 15 | M�xico | 39 | Ixtapaluca | 1 | IXTAPALUCA | 075A | 150390001075A | 22876 | 6160 | ... | 13.6 | 4.3 | 32.3 | 0.7 | 1.7 | 1.1 | 0.3 | 0.0 | 0.0 | Bajo |
1 rows × 25 columns
Podemos finalmente utilizar funciones junto con Pandas, tanto lambda como unas ya definidas:
def add (x):
y=x+1
return y
teams.apply(add)
| Internazionale | Rubentus | |
|---|---|---|
| Europa League | 4 | 4 |
| Champions | 4 | 3 |
| Ligas Robadas | 1 | 8 |
| Arbitros comprados | 1 | 107 |
teams.apply(lambda x: x+1)
Ordenar¶
teams.sort_values(by = 'Internazionale', ascending=False).head()
| Internazionale | Rubentus | |
|---|---|---|
| Europa League | 3 | 3 |
| Champions | 3 | 2 |
| Ligas Robadas | 0 | 7 |
| Arbitros comprados | 0 | 106 |
teams.sort_values(by = ['Internazionale','Rubentus'], ascending=[False,True]).head()
| Internazionale | Rubentus | |
|---|---|---|
| Champions | 3 | 2 |
| Europa League | 3 | 3 |
| Ligas Robadas | 0 | 7 |
| Arbitros comprados | 0 | 106 |
Pivot, stack/unstack, melt¶
Podemos operar nuestras tablas para poder hacer operaciones con más facilidad con ellas. en particular tenemos 3 funciones:
Pivot
Stack/Unstack
Melt
Creamos un Db para ver estas funciones de Pandas:
import pandas._testing as tm
def unpivot(frame):
N, K = frame.shape
data = {
"value": frame.to_numpy().ravel("F"),
"variable": np.asarray(frame.columns).repeat(N),
"date": np.tile(np.asarray(frame.index), K),
}
return pd.DataFrame(data, columns=["date", "variable", "value"])
df = unpivot(tm.makeTimeDataFrame(3))
df
| date | variable | value | |
|---|---|---|---|
| 0 | 2000-01-03 | A | -1.131902 |
| 1 | 2000-01-04 | A | -0.556481 |
| 2 | 2000-01-05 | A | -1.137324 |
| 3 | 2000-01-03 | B | -0.406190 |
| 4 | 2000-01-04 | B | -0.705153 |
| 5 | 2000-01-05 | B | -0.040682 |
| 6 | 2000-01-03 | C | 1.342086 |
| 7 | 2000-01-04 | C | 1.085131 |
| 8 | 2000-01-05 | C | -0.136259 |
| 9 | 2000-01-03 | D | 0.370952 |
| 10 | 2000-01-04 | D | 0.077812 |
| 11 | 2000-01-05 | D | -1.279112 |
df.sort_values(by=["date"])
| date | variable | value | |
|---|---|---|---|
| 0 | 2000-01-03 | A | -1.131902 |
| 3 | 2000-01-03 | B | -0.406190 |
| 6 | 2000-01-03 | C | 1.342086 |
| 9 | 2000-01-03 | D | 0.370952 |
| 1 | 2000-01-04 | A | -0.556481 |
| 4 | 2000-01-04 | B | -0.705153 |
| 7 | 2000-01-04 | C | 1.085131 |
| 10 | 2000-01-04 | D | 0.077812 |
| 2 | 2000-01-05 | A | -1.137324 |
| 5 | 2000-01-05 | B | -0.040682 |
| 8 | 2000-01-05 | C | -0.136259 |
| 11 | 2000-01-05 | D | -1.279112 |
Notamos que tenemos una serie de tiempo con distintas variables, podríamos por lo tanto seleccionar una variable en particular para analizarla:
df[df["variable"] == "A"]
| date | variable | value | |
|---|---|---|---|
| 0 | 2000-01-03 | A | -1.131902 |
| 1 | 2000-01-04 | A | -0.556481 |
| 2 | 2000-01-05 | A | -1.137324 |
Pero seguramente no es una manera eficiente de utilizar nuestra base. Resulta mucho más eficaz pivotear nuestra tabla, dejando los valores de las variables como columnas y sus valores como valores de la matriz. Por lo tanto la primera función que utilizaremos será la de pivotear la tabla:
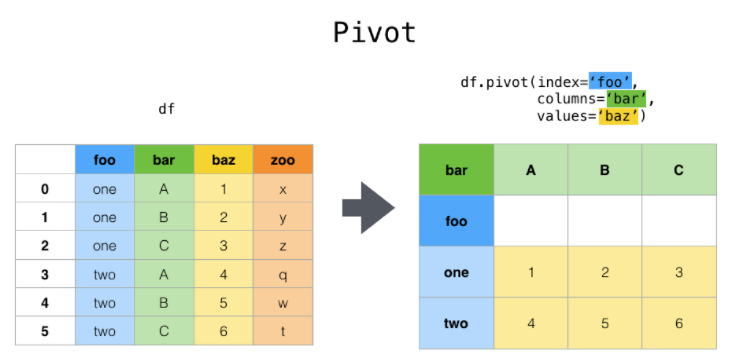
df.pivot(index="date", columns="variable", values="value")
| variable | A | B | C | D |
|---|---|---|---|---|
| date | ||||
| 2000-01-03 | -1.131902 | -0.406190 | 1.342086 | 0.370952 |
| 2000-01-04 | -0.556481 | -0.705153 | 1.085131 | 0.077812 |
| 2000-01-05 | -1.137324 | -0.040682 | -0.136259 | -1.279112 |
Si tenemos más que una columna con valores y siempre una variable para la que queremos pivotear, se jerarquizarán las columnas:
df["value2"] = df["value"] * 2
pivoted = df.pivot(index="date", columns="variable")
pivoted
| value | value2 | |||||||
|---|---|---|---|---|---|---|---|---|
| variable | A | B | C | D | A | B | C | D |
| date | ||||||||
| 2000-01-03 | -1.131902 | -0.406190 | 1.342086 | 0.370952 | -2.263805 | -0.812380 | 2.684172 | 0.741904 |
| 2000-01-04 | -0.556481 | -0.705153 | 1.085131 | 0.077812 | -1.112962 | -1.410305 | 2.170261 | 0.155623 |
| 2000-01-05 | -1.137324 | -0.040682 | -0.136259 | -1.279112 | -2.274647 | -0.081365 | -0.272517 | -2.558225 |
pivoted["value2"]
| variable | A | B | C | D |
|---|---|---|---|---|
| date | ||||
| 2000-01-03 | -2.263805 | -0.812380 | 2.684172 | 0.741904 |
| 2000-01-04 | -1.112962 | -1.410305 | 2.170261 | 0.155623 |
| 2000-01-05 | -2.274647 | -0.081365 | -0.272517 | -2.558225 |
Si nuestro indice no es unico obtendremos un error de la aplicación de la fuanción pivot(). En este caso tendremos que utilizar pivot_table().
Stack/Unstack¶
Relacionado a la operación de pivot, stack y unstack lo podemos utilizar en series y data frame. Estos objectos son creados para trabajar con bases con indices multiples:
Stack: pivotea nuestra tabla regresandonos un data frame con un indice con un nuevo nivel más interno
Unstack: es la operación inversapivotea un renglón que se vuelve columna, trasformando uno de los indices interiores en columna
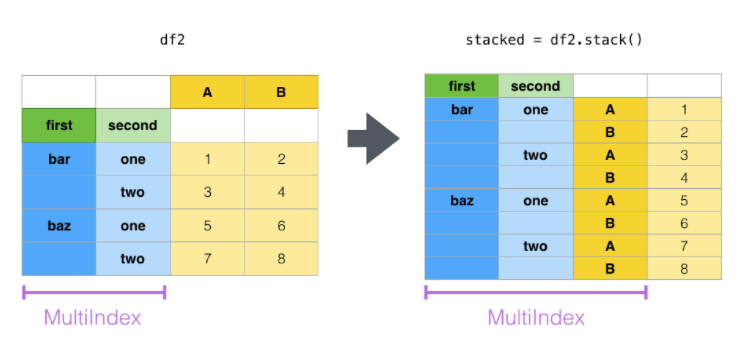
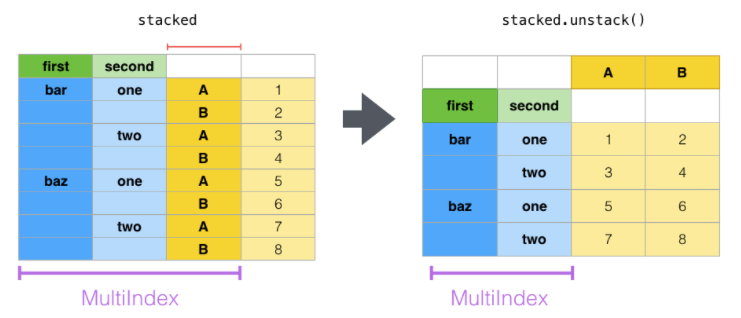
tuples = list(
zip(
*[
["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"],
["one", "two", "one", "two", "one", "two", "one", "two"],
]
)
)
index = pd.MultiIndex.from_tuples(tuples, names=["first", "second"])
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=["A", "B"])
df2 = df[:4]
df2
| A | B | ||
|---|---|---|---|
| first | second | ||
| bar | one | 1.066418 | 0.144467 |
| two | -0.402300 | -1.032331 | |
| baz | one | -1.001775 | -0.168402 |
| two | -0.437370 | -1.578787 |
La función stack comprime un nivel entre las columnas del Dataframe para producir:
Una serie si hay solo un indice columna
Un Dataframe, en el caso tengamos un multi indice
DSi la columna tiene un indice multiple se puede escoger sobre cual hacer el stack. El nivel «stacked» se vuelve el nuevo indice de nivel más bajo con respecto a las coluumnas.
stacked = df2.stack()
stacked
first second
bar one A 1.066418
B 0.144467
two A -0.402300
B -1.032331
baz one A -1.001775
B -0.168402
two A -0.437370
B -1.578787
dtype: float64
La operación unstack hace la operación inversa y de cajon «unstacka» el ultimpo nivel:
stacked.unstack()
| A | B | ||
|---|---|---|---|
| first | second | ||
| bar | one | -0.542989 | -1.528475 |
| two | -1.179154 | 1.489257 | |
| baz | one | 2.394403 | 0.076994 |
| two | 0.655607 | 0.568373 |
Pero podemos decidir con respecto a cuál nivel hacerlo:
stacked.unstack(1)
| second | one | two | |
|---|---|---|---|
| first | |||
| bar | A | -0.542989 | -1.179154 |
| B | -1.528475 | 1.489257 | |
| baz | A | 2.394403 | 0.655607 |
| B | 0.076994 | 0.568373 |
stacked.unstack(0)
| first | bar | baz | |
|---|---|---|---|
| second | |||
| one | A | -0.542989 | 2.394403 |
| B | -1.528475 | 0.076994 | |
| two | A | -1.179154 | 0.655607 |
| B | 1.489257 | 0.568373 |
Notamos que cuando hacemos las operaciones de stack y unstack se ordenarán implicitamente los niveles involucrados. Por lo tantos obtendremos una versión ordenada del data frame original.
Podemos hacer esto también pasando como argumento multiples indices:
columns = pd.MultiIndex.from_tuples([ ("A", "cat", "long"),("B", "cat", "long"),("A", "dog", "short"),
("B", "dog", "short") ], names=["exp", "animal", "hair_length"],)
df = pd.DataFrame(np.random.randn(4, 4), columns=columns)
df
| exp | A | B | A | B |
|---|---|---|---|---|
| animal | cat | cat | dog | dog |
| hair_length | long | long | short | short |
| 0 | -0.551227 | -1.915583 | 0.234669 | 1.909948 |
| 1 | 1.888322 | 0.653376 | 1.680208 | 0.987749 |
| 2 | 1.625931 | -0.140697 | 0.700946 | -1.610856 |
| 3 | -1.345385 | -1.033005 | -0.119125 | 1.576757 |
df.stack(level=["animal", "hair_length"])
| exp | A | B | ||
|---|---|---|---|---|
| animal | hair_length | |||
| 0 | cat | long | -0.551227 | -1.915583 |
| dog | short | 0.234669 | 1.909948 | |
| 1 | cat | long | 1.888322 | 0.653376 |
| dog | short | 1.680208 | 0.987749 | |
| 2 | cat | long | 1.625931 | -0.140697 |
| dog | short | 0.700946 | -1.610856 | |
| 3 | cat | long | -1.345385 | -1.033005 |
| dog | short | -0.119125 | 1.576757 |
df.stack(level=[1, 2])
| exp | A | B | ||
|---|---|---|---|---|
| animal | hair_length | |||
| 0 | cat | long | -0.551227 | -1.915583 |
| dog | short | 0.234669 | 1.909948 | |
| 1 | cat | long | 1.888322 | 0.653376 |
| dog | short | 1.680208 | 0.987749 | |
| 2 | cat | long | 1.625931 | -0.140697 |
| dog | short | 0.700946 | -1.610856 | |
| 3 | cat | long | -1.345385 | -1.033005 |
| dog | short | -0.119125 | 1.576757 |
El programa maneja también de manera eficaz la falta de algunas etiquetas:
columns = pd.MultiIndex.from_tuples(
[
("A", "cat"),
("B", "dog"),
("B", "cat"),
("A", "dog"),
],
names=["exp", "animal"],
)
index = pd.MultiIndex.from_product(
[("bar", "baz", "foo", "qux"), ("one", "two")], names=["first", "second"]
)
df = pd.DataFrame(np.random.randn(8, 4), index=index, columns=columns)
df2 = df.iloc[[0, 1, 2, 4, 5, 7]]
df2
| exp | A | B | A | ||
|---|---|---|---|---|---|
| animal | cat | dog | cat | dog | |
| first | second | ||||
| bar | one | 0.354118 | 1.595198 | 1.117064 | -0.652456 |
| two | -0.519498 | -0.029032 | -0.065620 | -1.508366 | |
| baz | one | -0.264872 | -0.556633 | 0.837041 | 1.135980 |
| foo | one | 1.091923 | -0.619072 | -1.397275 | 0.882972 |
| two | -0.339650 | -0.139170 | -0.861445 | 0.771828 | |
| qux | two | -1.387585 | -0.458812 | -1.449294 | -0.503080 |
Que pasa si ahora llamamos la funciona stack con respecto al nivel exp:
df2.stack("exp")
| animal | cat | dog | ||
|---|---|---|---|---|
| first | second | exp | ||
| bar | one | A | 0.354118 | -0.652456 |
| B | 1.117064 | 1.595198 | ||
| two | A | -0.519498 | -1.508366 | |
| B | -0.065620 | -0.029032 | ||
| baz | one | A | -0.264872 | 1.135980 |
| B | 0.837041 | -0.556633 | ||
| foo | one | A | 1.091923 | 0.882972 |
| B | -1.397275 | -0.619072 | ||
| two | A | -0.339650 | 0.771828 | |
| B | -0.861445 | -0.139170 | ||
| qux | two | A | -1.387585 | -0.503080 |
| B | -1.449294 | -0.458812 |
Cuando hacemos la operación inversa de unstack y falta algun dato en la
df3 = df.iloc[[0, 1, 4, 7], [1, 2]]
df3
| exp | B | ||
|---|---|---|---|
| animal | dog | cat | |
| first | second | ||
| bar | one | 1.595198 | 1.117064 |
| two | -0.029032 | -0.065620 | |
| foo | one | -0.619072 | -1.397275 |
| qux | two | -0.458812 | -1.449294 |
df3.unstack()
| exp | B | |||
|---|---|---|---|---|
| animal | dog | cat | ||
| second | one | two | one | two |
| first | ||||
| bar | 1.595198 | -0.029032 | 1.117064 | -0.065620 |
| foo | -0.619072 | NaN | -1.397275 | NaN |
| qux | NaN | -0.458812 | NaN | -1.449294 |
O podemos especificar con que valor llenarlo:
df3.unstack(fill_value="ciao")
| exp | B | |||
|---|---|---|---|---|
| animal | dog | cat | ||
| second | one | two | one | two |
| first | ||||
| bar | 1.595198 | -0.029032 | 1.117064 | -0.06562 |
| foo | -0.619072 | ciao | -1.397275 | ciao |
| qux | ciao | -0.458812 | ciao | -1.449294 |
Melt¶
La función melt no será parrticularmente utíl cuando una o más columnas representan un identificador y las demás son «valores». El nombre de estas columnas pueden ser sostituydos con el var_name o el value_name
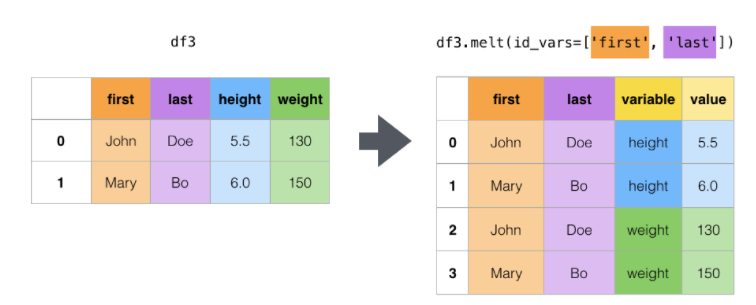
cheese = pd.DataFrame(
{
"first": ["John", "Mary"],
"last": ["Doe", "Bo"],
"height": [5.5, 6.0],
"weight": [130, 150],
}
)
cheese
| first | last | height | weight | |
|---|---|---|---|---|
| 0 | John | Doe | 5.5 | 130 |
| 1 | Mary | Bo | 6.0 | 150 |
cheese.melt(id_vars=["first", "last"])
| first | last | variable | value | |
|---|---|---|---|---|
| 0 | John | Doe | height | 5.5 |
| 1 | Mary | Bo | height | 6.0 |
| 2 | John | Doe | weight | 130.0 |
| 3 | Mary | Bo | weight | 150.0 |
cheese.melt(id_vars=["first", "last"], var_name="quantity")
| first | last | quantity | value | |
|---|---|---|---|---|
| 0 | John | Doe | height | 5.5 |
| 1 | Mary | Bo | height | 6.0 |
| 2 | John | Doe | weight | 130.0 |
| 3 | Mary | Bo | weight | 150.0 |
Cuando utilizamos esta función el indice viene ignorado. El indice original puede ser mantenido con la función ignore_index=F, aunque estto determinará unos duplicados.
index = pd.MultiIndex.from_tuples([("person", "A"), ("person", "B")])
cheese = pd.DataFrame(
{
"first": ["John", "Mary"],
"last": ["Doe", "Bo"],
"height": [5.5, 6.0],
"weight": [130, 150],
},
index=index,
)
cheese
| first | last | height | weight | ||
|---|---|---|---|---|---|
| person | A | John | Doe | 5.5 | 130 |
| B | Mary | Bo | 6.0 | 150 |
cheese.index
MultiIndex([('person', 'A'),
('person', 'B')],
)
cheese.melt(id_vars=["first", "last"])
| first | last | variable | value | |
|---|---|---|---|---|
| 0 | John | Doe | height | 5.5 |
| 1 | Mary | Bo | height | 6.0 |
| 2 | John | Doe | weight | 130.0 |
| 3 | Mary | Bo | weight | 150.0 |
cheese.melt(id_vars=["first", "last"], ignore_index=False)
cheese.index
MultiIndex([('person', 'A'),
('person', 'B')],
)
cheese.melt(id_vars=["first", "last"], ignore_index=False).index
MultiIndex([('person', 'A'),
('person', 'B'),
('person', 'A'),
('person', 'B')],
)
cheese.melt(id_vars=["first", "last"]).index
RangeIndex(start=0, stop=4, step=1)
Finalmente podemo utilizar la función wide_long para ajustar datos de panel, resulta menos felxible de melt pero mucho más intuitiva:
dft = pd.DataFrame(
{
"A1970": {0: "a", 1: "b", 2: "c"},
"A1980": {0: "d", 1: "e", 2: "f"},
"B1970": {0: 2.5, 1: 1.2, 2: 0.7},
"B1980": {0: 3.2, 1: 1.3, 2: 0.1},
"X": dict(zip(range(3), np.random.randn(3))),
}
)
dft["id"] = dft.index
dft
| A1970 | A1980 | B1970 | B1980 | X | id | |
|---|---|---|---|---|---|---|
| 0 | a | d | 2.5 | 3.2 | 1.242517 | 0 |
| 1 | b | e | 1.2 | 1.3 | -1.772425 | 1 |
| 2 | c | f | 0.7 | 0.1 | 1.667115 | 2 |
pd.wide_to_long(dft, ["A", "B"], i="id", j="year")
| X | A | B | ||
|---|---|---|---|---|
| id | year | |||
| 0 | 1970 | 1.242517 | a | 2.5 |
| 1 | 1970 | -1.772425 | b | 1.2 |
| 2 | 1970 | 1.667115 | c | 0.7 |
| 0 | 1980 | 1.242517 | d | 3.2 |
| 1 | 1980 | -1.772425 | e | 1.3 |
| 2 | 1980 | 1.667115 | f | 0.1 |
Podemos combinar todo esto con group_by y funciónes estadisticas:
df
| exp | A | B | A | ||
|---|---|---|---|---|---|
| animal | cat | dog | cat | dog | |
| first | second | ||||
| bar | one | 0.354118 | 1.595198 | 1.117064 | -0.652456 |
| two | -0.519498 | -0.029032 | -0.065620 | -1.508366 | |
| baz | one | -0.264872 | -0.556633 | 0.837041 | 1.135980 |
| two | -1.249914 | -0.268238 | -0.775254 | 0.397196 | |
| foo | one | 1.091923 | -0.619072 | -1.397275 | 0.882972 |
| two | -0.339650 | -0.139170 | -0.861445 | 0.771828 | |
| qux | one | 0.281156 | -0.394542 | 0.013684 | 0.114945 |
| two | -1.387585 | -0.458812 | -1.449294 | -0.503080 | |
df.stack().mean(1).unstack()
| animal | cat | dog | |
|---|---|---|---|
| first | second | ||
| bar | one | 0.735591 | 0.471371 |
| two | -0.292559 | -0.768699 | |
| baz | one | 0.286084 | 0.289674 |
| two | -1.012584 | 0.064479 | |
| foo | one | -0.152676 | 0.131950 |
| two | -0.600548 | 0.316329 | |
| qux | one | 0.147420 | -0.139799 |
| two | -1.418440 | -0.480946 |
df.groupby(level=1, axis=1).mean()
| animal | cat | dog | |
|---|---|---|---|
| first | second | ||
| bar | one | 0.735591 | 0.471371 |
| two | -0.292559 | -0.768699 | |
| baz | one | 0.286084 | 0.289674 |
| two | -1.012584 | 0.064479 | |
| foo | one | -0.152676 | 0.131950 |
| two | -0.600548 | 0.316329 | |
| qux | one | 0.147420 | -0.139799 |
| two | -1.418440 | -0.480946 |
df.stack().groupby(level=1).mean()
| exp | A | B |
|---|---|---|
| second | ||
| one | 0.367971 | 0.074433 |
| two | -0.542384 | -0.505858 |
df.mean().unstack(0)
| exp | A | B |
|---|---|---|
| animal | ||
| cat | -0.254290 | -0.322637 |
| dog | 0.079877 | -0.108788 |